the purpose of activation function is to increase the non-linearity of ML model, so that classification can be done better. it can also be imagined as twisting the space to find linear boundary
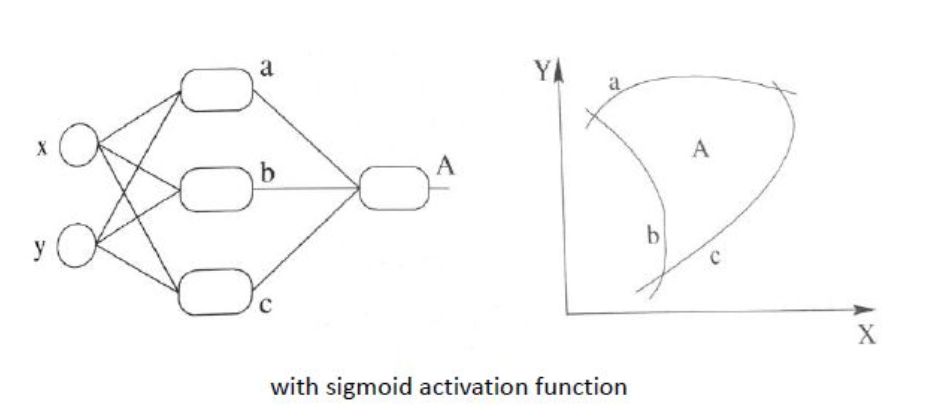
type of activation functions
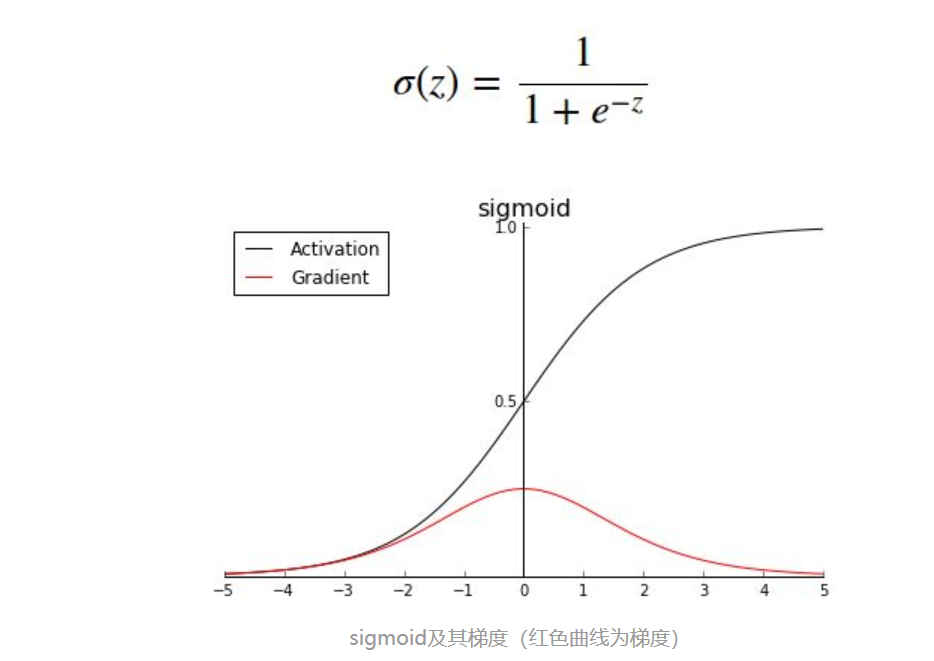
sigmoid
usually used for classification, output is squeezed into (0, 1)zone
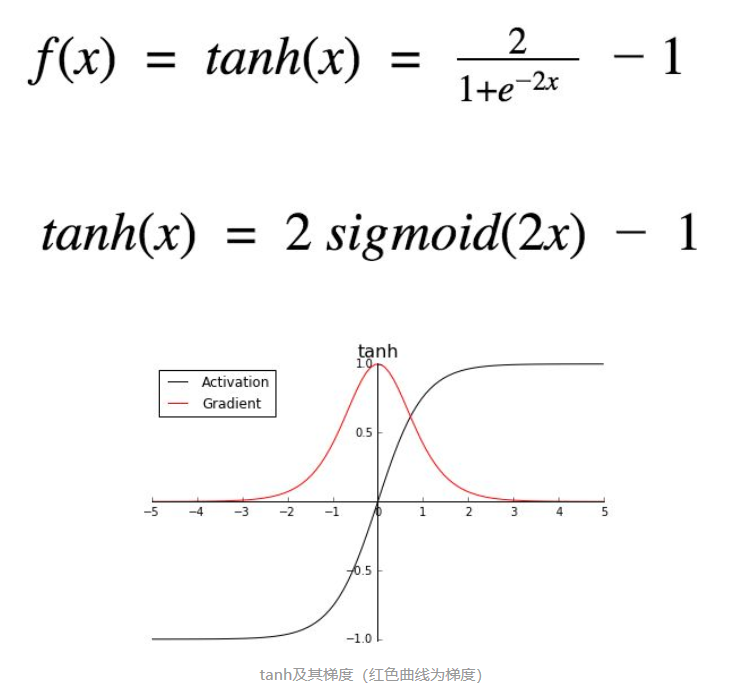
tanh
it is similar to sigmoid, but output is in (-1, 1) zone.
Its max. gradient is larger than sigmoid, and it decrease faster than sigmoid (possibly gradient vanishing problem)
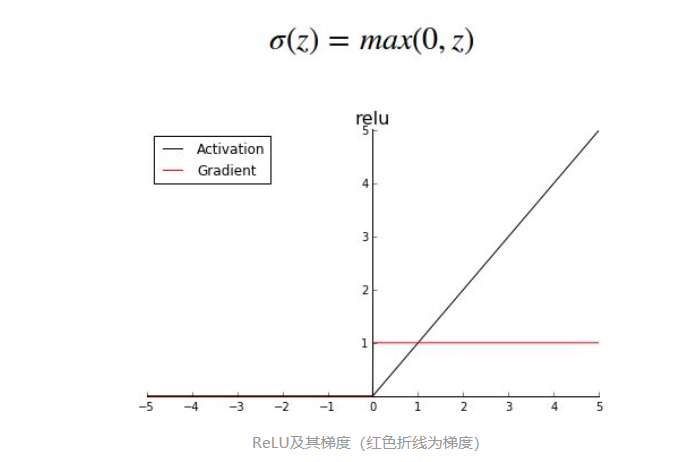
ReLU
relu works like a gate-keeper (keep negative value out with dead neutron)
It does not have the gradient vanishing problem (gradient either be 1 or 0)
 it is less susceptible to vanishing gradients that prevent deep models from being trained, although it can suffer from other problems like saturated or “dead” units.
relu has sparse activation ability.
it is less susceptible to vanishing gradients that prevent deep models from being trained, although it can suffer from other problems like saturated or “dead” units.
relu has sparse activation ability.
sparsity
sparsity means more zeros in the parameter matrix
Feature selection
non-important parameters will be automatically neglected, only a few important paramters will be kept for next layer, this increase modell stability during prediction
Interpretability
problem can be explained with key factors
selection of activation function
- for Hidden Layer: Multilayer Perceptron (MLP): ReLU activation function. Convolutional Neural Network (CNN): ReLU activation function. Recurrent Neural Network: Tanh and/or Sigmoid activation function.
- for output layer: Regression: One node, linear activation. Binary Classification: One node, sigmoid activation. Multiclass Classification: One node per class, softmax activation. Multilabel Classification: One node per class, sigmoid activation.