to use large learning rate at the beginning, and decays step by step, function tf.train.exponential_decay() can be used large learning rate for simply task can lead to result vibration!(not larger than 0.1 if layer deeper than 7)
tf.train.exponential_decay(learning rate, global_step, decay_steps, decay_rate)
- learing rate: initial learning rate
- global_step: iteration step
- decay_steps: can be set to number of batches
- decay_rate: rate of decay
- decayed_learning_rate=learining_rate*decay_rate^(global_step/decay_steps)
Implementation
global_step = tf.Variable(0)
learning_rate = tf.train.exponential_decay(0.1, global_step, 100, 0.96, staircase=True)# create learing rate instance
learning_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(....., global_step=global_step) # use changing learning rate
a good learning rate
to find a good learning rate we could use fastai library to make a plot of learning rate and loss
learner.lr_find()
learner.sched.plot() 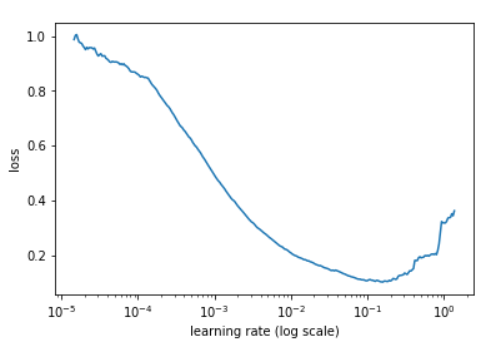
go one order of magnitude before the minimum is the best learning rate
using different learning rate on different layers
larger learning rate in the front layers and smaller in the rear
var1 = tf.trainable_variables()[0:40]
var2 = tf.trainable_variables()[40:]
train_op1 = GradientDescentOptimizer(0.00001).minimize(loss, var_list=var1)
train_op2 = GradientDescentOptimizer(0.0001).minimize(loss, var_list=var2)
train_op = tf.group(train_op1, train_op2)
transfer learning
with tf.Graph().as_default():
variables_to_restore = []
variables_to_train = []
for var in slim.get_model_variables():
excluded = False
for exclusion in fine_tune_layers:
if var.op.name.startswith(exclusion):
excluded = True
break
if not excluded:
variables_to_restore.append(var)
else:
variables_to_train.append(var)