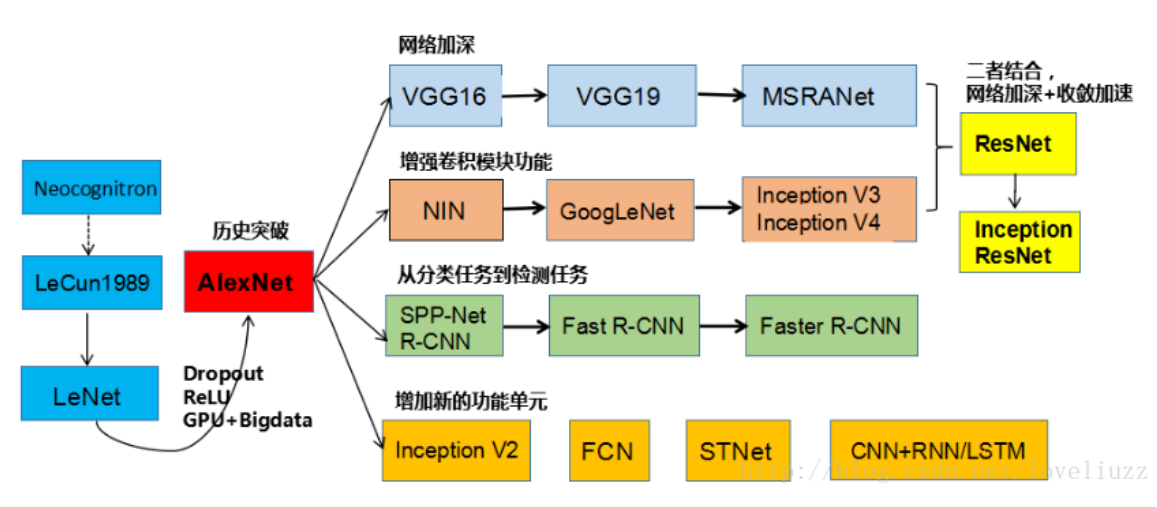
development of CNN
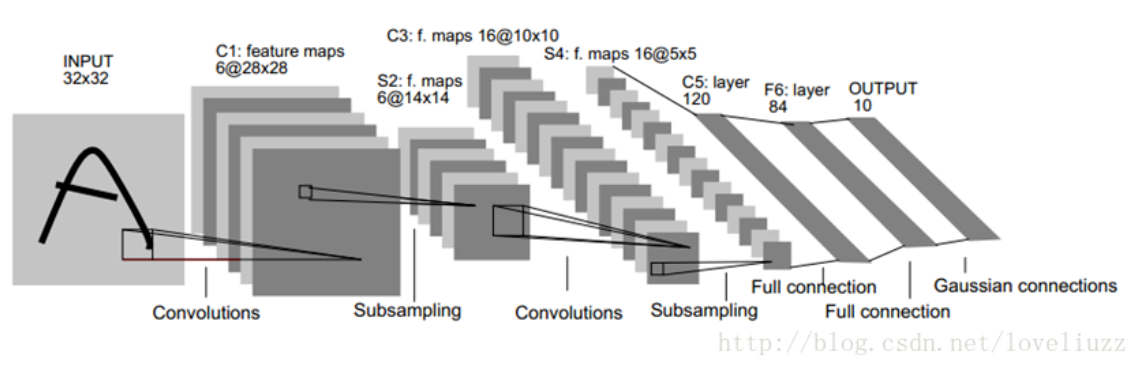
LeNet
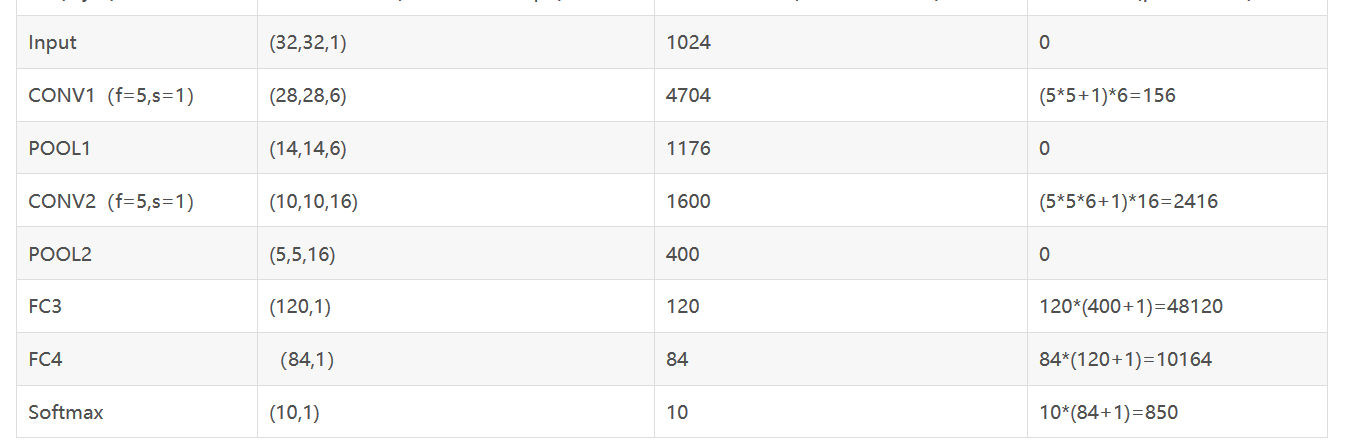
there are 2 conv layers, 2 pooling layers, 2 fc layers and 1 output layer, tanh or sigmoid activation function
-
Conv1: 6 kernels with size of 5x5 , stride=1, padding=0
purpose is to increase the feature signal and decrease noise -
Average Pool1: 2x2 filter, stride=2, padding=0
purpose is to decrease data size and keep usefully information at the same time and avoid overfitting - Conv2: 16 kernels with size of 5x5, stride=1, padding=0
- Average Pool2: 2x2 filter, stride=2, padding=0
- Fc3: output_node=120
- Fc4: output_node=84
- out5: softmax
AlexNet
there are 5 conv layers, 3 pooling layers, 2 fc layers, 1 output layer implemented dropout use ReLu activation max. pooling
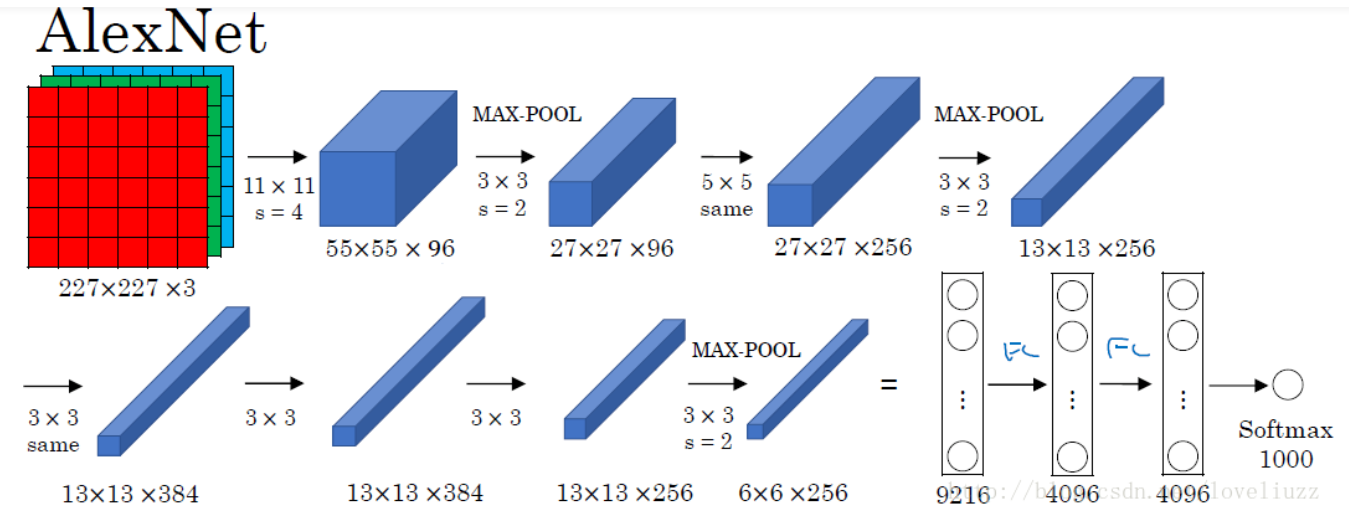
AlexNet is to be considered as modul design. For example for converlution conv and pooling are combined together, functions(activation and pooling) are inserted inbetween to control the data
- modul1/modul2:
structure: conv+ReLu+Pooling+Normalization conv: 96(conv1)/256(conv2) kernels with size of 11x11(conv1)/5x5(conv2), stride=4(conv1)/1(conv2), padding=0(conv1)/2(conv2) max pooling: 3x3 filter, stride=2, padding=0
norm: local_size=5 - modul3/modul4:
structure: conv+ReLu (no pooing because of smaller feature size) conv: 384 kernels with size of 3x3, stride=1, padding=1 -
modul5
structure: conv+ReLu+pooling conv: 256 kernels with size of 3x3, stride=1, padding=1 max pooling: 3x3 filter, stride=2 - modul6/modul7/modul8
structure: fc+ReLu+dropout fc: output_node=4096(fc6 and fc7) /class_num(fc8)
VGG16
it uses smaller conv kernels to construct deeper network, so that more complex model can be learned there are 16 hidden layers in VGG16: 13 conv layers, 5 pooling layers(not couted into 16), 2 fc layer, 1 output layer the conv layers are to extract feature and pooling layers are to compress the image to smaller size the VGG19 has almost same performance with VGG16 but with deeper networks since the training of VGG model takes lots of time, it is prefered to use open pretrained modells, which can be found in open libraries, to train other modell further (open library: https://github.com/machrisaa/tensorflow-vgg, https://www.cs.toronto.edu/~frossard/post/vgg16/)
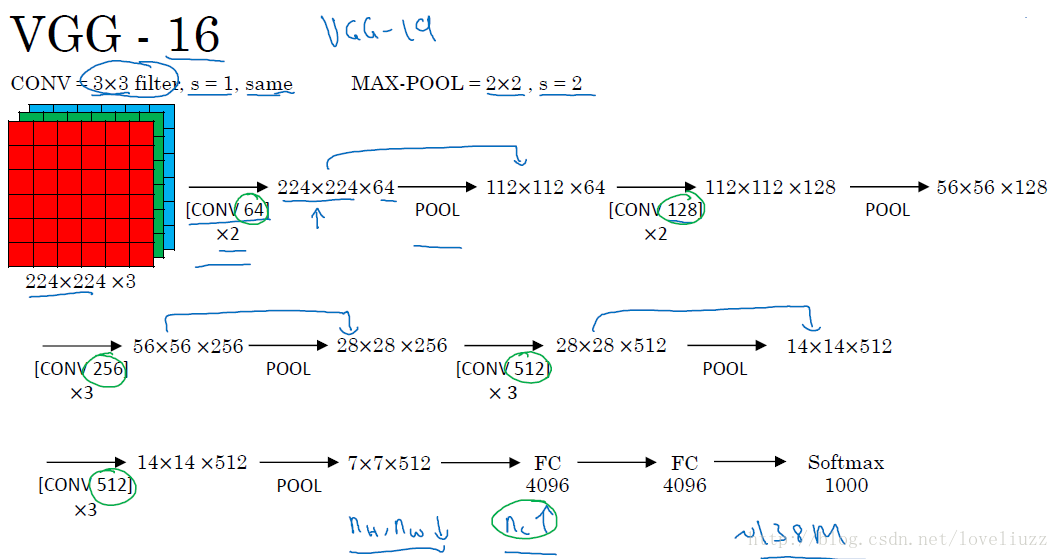
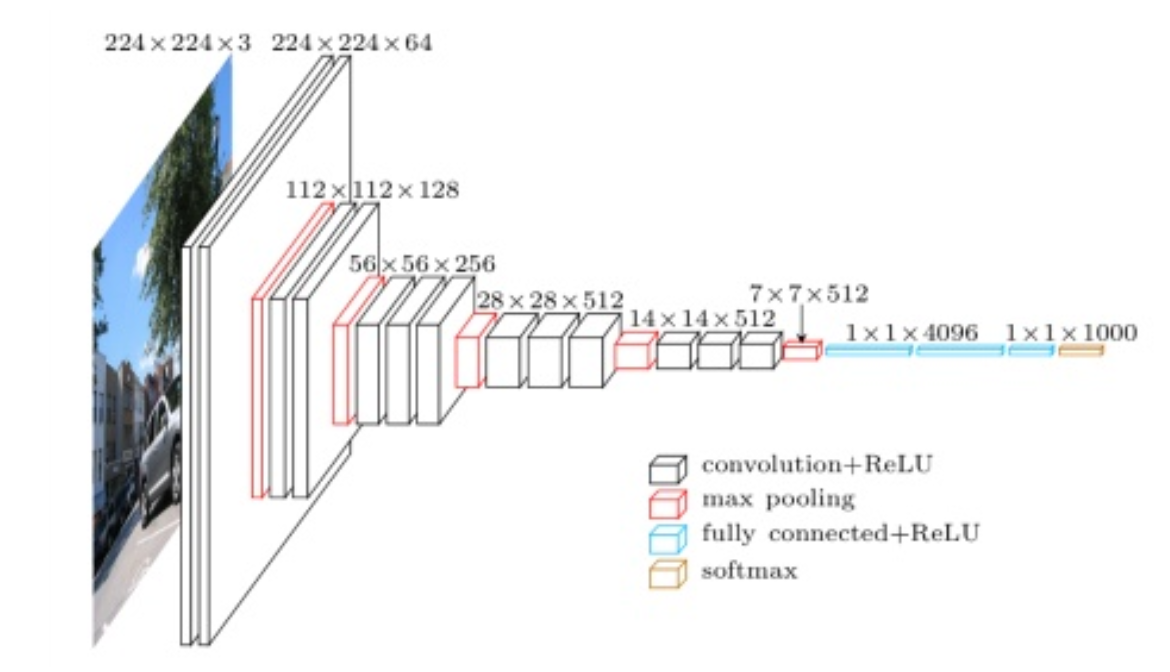
compared with AlexNet, the stack of three 3x3 conv layers has same effective receptive field as one 7x7 conv layer, but fewer parameters, much deeper and more non-linearities
- block1 structure: [Conv64]x2(incl. ReLu)+Pooling conv: 64 kernels with size of 3x3, stride=1, padding=’SAME’ max pooling: 2x2 filter, stride=2
- block2 structure: [Conv128]x2(incl. ReLu)+Pooling conv: 128 kernels with size of 3x3, stride=1, padding=’SAME’ max pooling: 2x2 filter, stride=2
- block3 structure: [Conv256]x3(incl. ReLu)+Pooling conv: 256 kernels with size of 3x3, stride=1, padding=’SAME’ max pooling: 2x2 filter, stride=2
- block4 structure: [Conv512]x3(incl. ReLu)+Pooling conv: 512 kernels with size of 3x3, stride=1, padding=’SAME’ max pooling: 2x2 filter, stride=2
- block5 structure: [Conv512]x3(incl. ReLu)+Pooling conv: 512 kernels with size of 3x3, stride=1, padding=’SAME’ max pooling: 2x2 filter, stride=2
- block6 structure: [fc4096]x2(incl. ReLu)
- block7 structure: [fc] with class_name output nodes