Densely Connected Convolutional Networks (DenseNets)
Each layer has direct access to the gradients from the loss function and the original input signal, leading to an implicit deep supervision

 comopared with ResNet, it is less costly in computation due to less parameters while at the same time has the same accuracy; better generalization performance with small datasets (no data augmentation needed)
gradient vanishing problem is enlightened because of earlier feature reuse
comopared with ResNet, it is less costly in computation due to less parameters while at the same time has the same accuracy; better generalization performance with small datasets (no data augmentation needed)
gradient vanishing problem is enlightened because of earlier feature reuse
structure
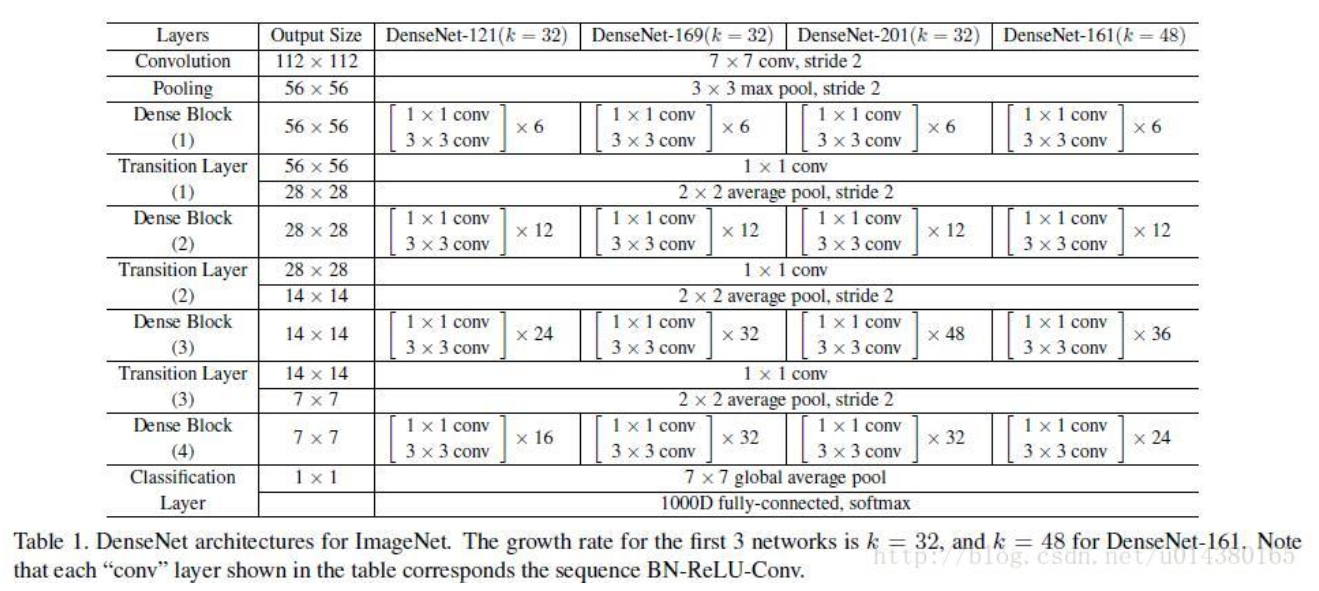
the input will be first processed with [7x7] kernel (stride=2) with output channel 2k and max pooled with [3x3] filter with stride of 2 before going into DenseBlock. Afterwards is repetation of DenseBlock and transition. at the end is global average pooling with [7x7] filter and 1000 fc and softsmax classification
configuration for ImageNet dataset is as following
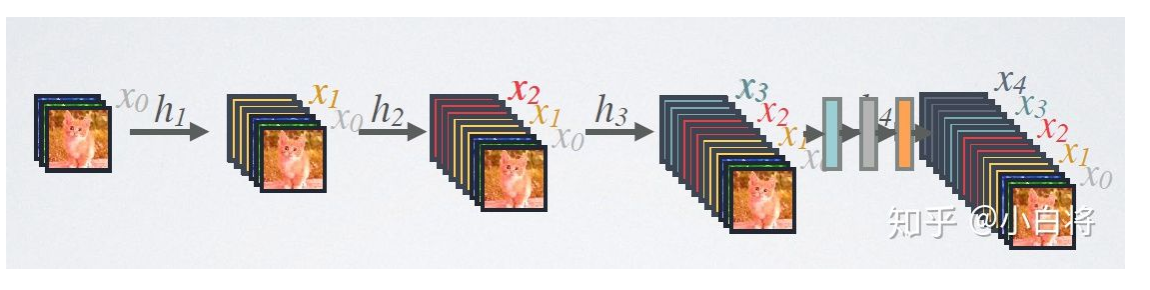
- The size of feature maps between dense blocks needs to be the same for channel-wise concatenation. DenseNet utilizes Dense Block and transition layer to solve the problem. Dense Blocks consist of multi-bottleneck layers with same feature map size. Transition Layer reduces feature map size between neighboring Dense Blocks with pooling
- DenseBlock layer:
- input image size 32x32: DenseNet contain 3 DenseBlocks with feature map size [32x32], [16x16] and [8x8]. Every DenseBlock has same number of feature channels. After the last DenseBlock is global AvgPooling layer and softmax layer. All [3x3] conv is done with padding=’SAME’ to keep feature map size constant
- input image size 224x224: contains 4 DenseBlocks
- Bottleneck layer : structure is BN-ReLU-Conv(1x1)-BN-ReLU-Conv(3x3), BN-ReLU-Conv(1x1) purpose is to reduce feature maps size and increase channels to 4k, BN-ReLU-Conv(3x3) is the Hl operation. DenseNet with bottleneck layer is called DenseNet-B
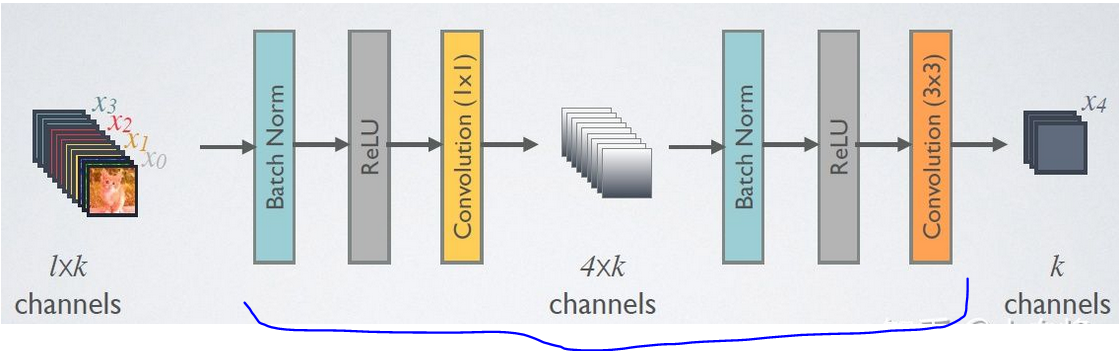
- transition layer:structure is BN+ReLU+1x1 Conv+2x2 AvgPooling. purpose is to reduce feature map size and compress feature channels, output channel is theta * m (m is input channels, /theta is compression factor, 0<theta<1). if theta <1 then the DenseNet is called DenseNet-C. DenseNet with both bottleneck and transition layers is called DenseNet-BC
- growth rate k: every bottleneck layer will generate k new feature map channels, so the lth layer has k0+k*(l-1) input feature maps. k is relatively small in DenseNet (e.g. 12)
- Hl operation
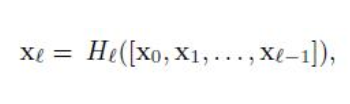 HI is BN-RELU-conv(3x3) operatioin, [x0,x1,…xl-1] represents concatenation of feature maps from 0 to l-1
HI is BN-RELU-conv(3x3) operatioin, [x0,x1,…xl-1] represents concatenation of feature maps from 0 to l-1 - configuration selection:
L: total network layers (Pooling adn BN is not counted)
- basic DenseNet: {L=40, k=12}, {L=100, k=12}, {L=40, k=24}
- DenseNet-BC: {L=100, k=12}, {L=250, k=12}, {L=190, k=40} for {L=40,k=12} there is 12((40-1(first conv)-2(transition))/3) layer in each DenseBlock
difference
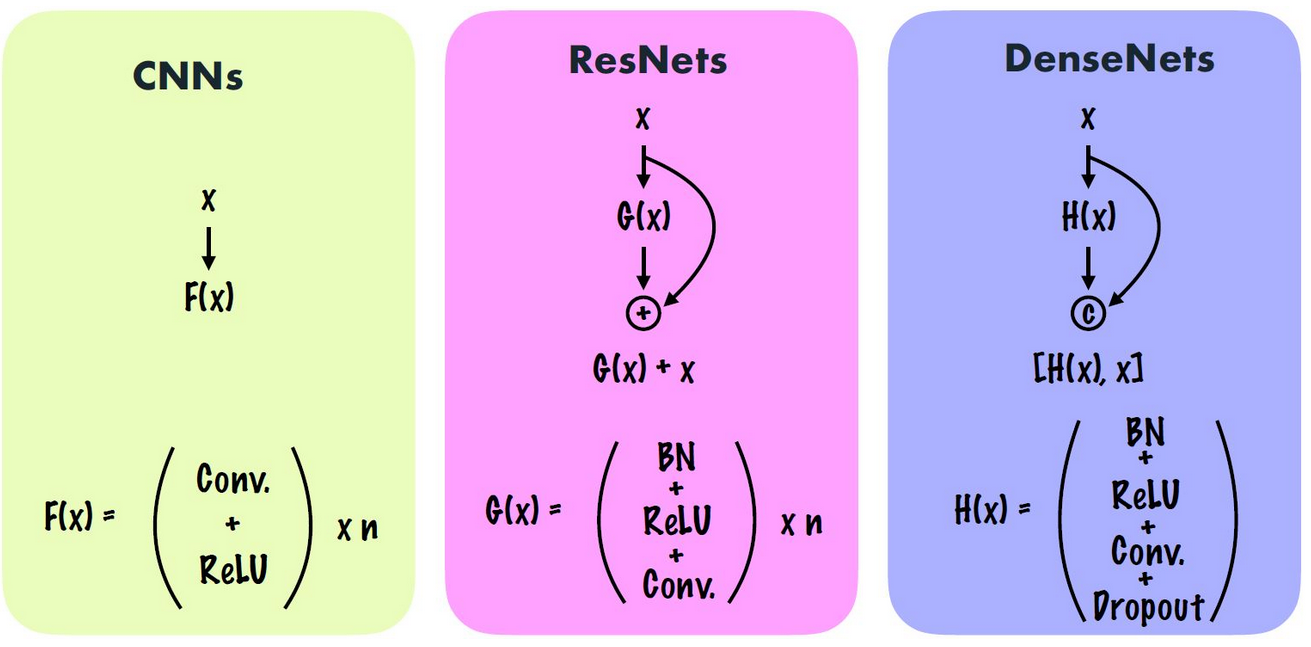
- traditional CNN is to find F(x) to fit the target;
- ResNet is element-wise addition of feature maps, to fit G(x) at 0 point rather than F(x) in large value range, which will reduce the probility of gradient vanishing problem
- DenseNet is channel-wise concatenation, to reuse the earlier extracted feature directly rather than extract them again