Apache Flume is an open-source, powerful, reliable and flexible system used to collect, aggregate and move large amounts of unstructured data from multiple data sources into HDFS/Hbase (for example) in a distributed fashion via it’s strong coupling with the Hadoop cluster.
Flume is dying or dead, because of
- Performance The processing speeds of Apache Flume is dependent on the buffer channel, which realistically cannot process upwards of a million events in most use-cases
- Order of events There is no guarantee that the events would be received by the sink in the same order it was sent from the client, which for some use-cases is absolutely unacceptable.
- Duplicate data There is a chance that some of the events are duplicated and sent more than once, that can at best be ignored, but on the other hand, can be disastrous.
flume OG(old generation)
flume OG utilizes architecture in layer: Agent, Collector and Storage
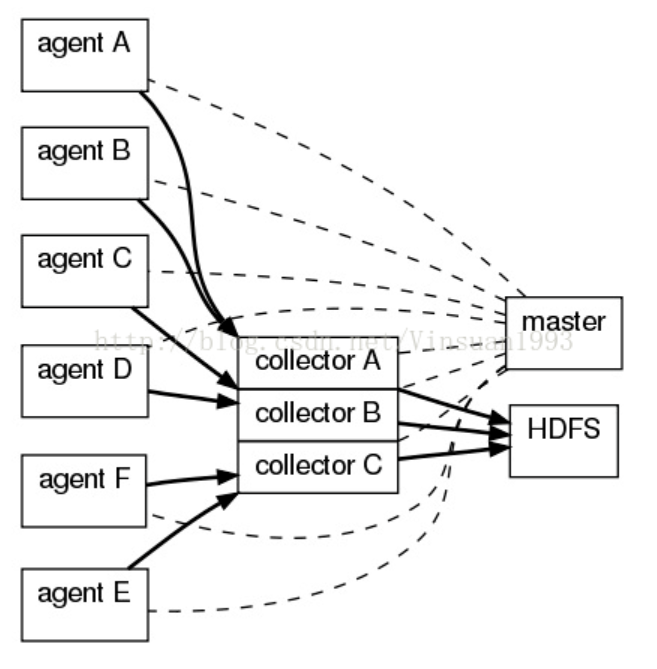
Agent
agent collect data to generate data flow
- collect data
- push sources extern system push data to flume
- polling sources
flume collects data from extern system with polling
Collector
collector aggregate data
Storage
Storage is an storage system, it can be file, hdfs, hive, hbase or other distributed storage system
Master
master coordinate and configure agent and collector flume implement multi-master and ZooKeeper to keep configuration consistency and high availability
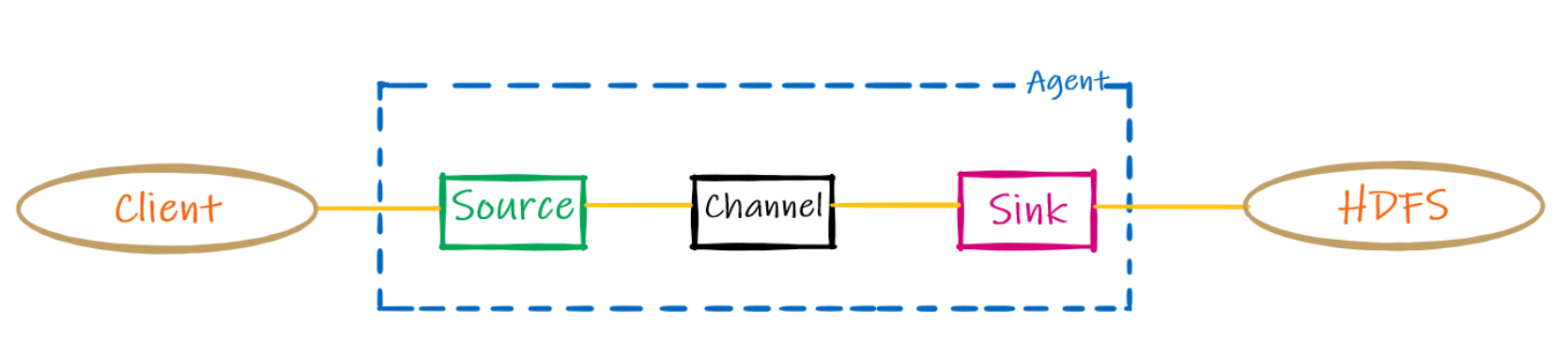
flume NG(new generation)
consist of source, sink and channel
- basic components
source
extract data from data geenrator and send data to one or more channel in flume event format. The extraction process can be event-driven or through frequent polling and is conducted by source-runners.
channel
it is a temporary storage container. The type of channel used is based upon a single factor, i.e. event reliability. Flume follows a transactional approach and doesn’t remove the event from the channel until it is moved into the sink and has received a confirmation from the subsequent sink runner.
- MemoryChannel higher performance but are also highly volatile and easily susceptible to failures
- JDBC performance is slowest but it provides the highest security against failures
- FileChannel it save data to disks to keep data completeness and consistency, it has moderate performance and is moderately secure against failures.
sink
send data to storage system (HDFS, Hbase, Hive, Elasticsearch etc.) in specified time interval
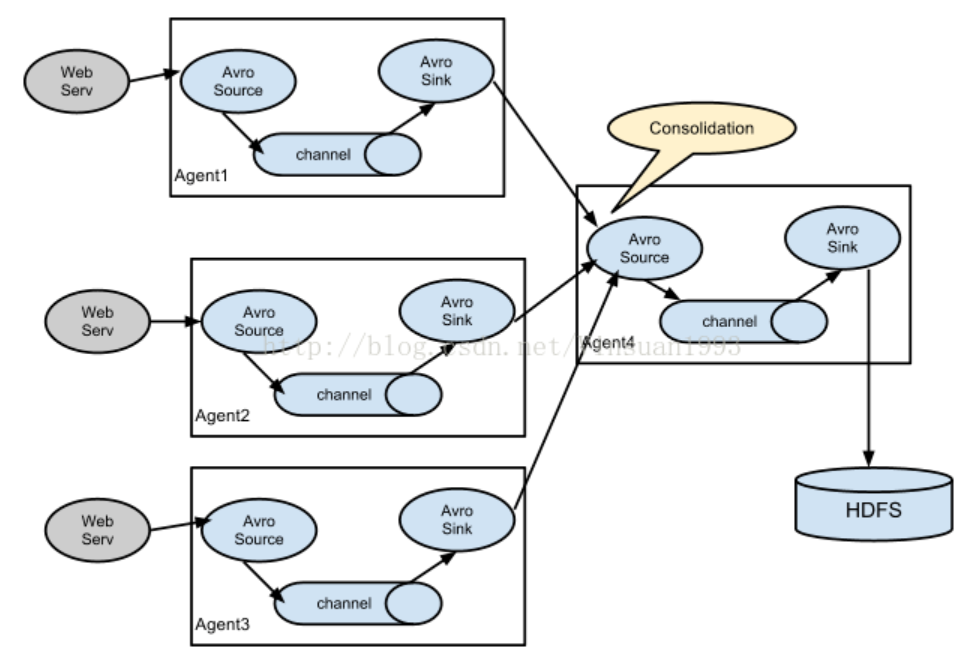
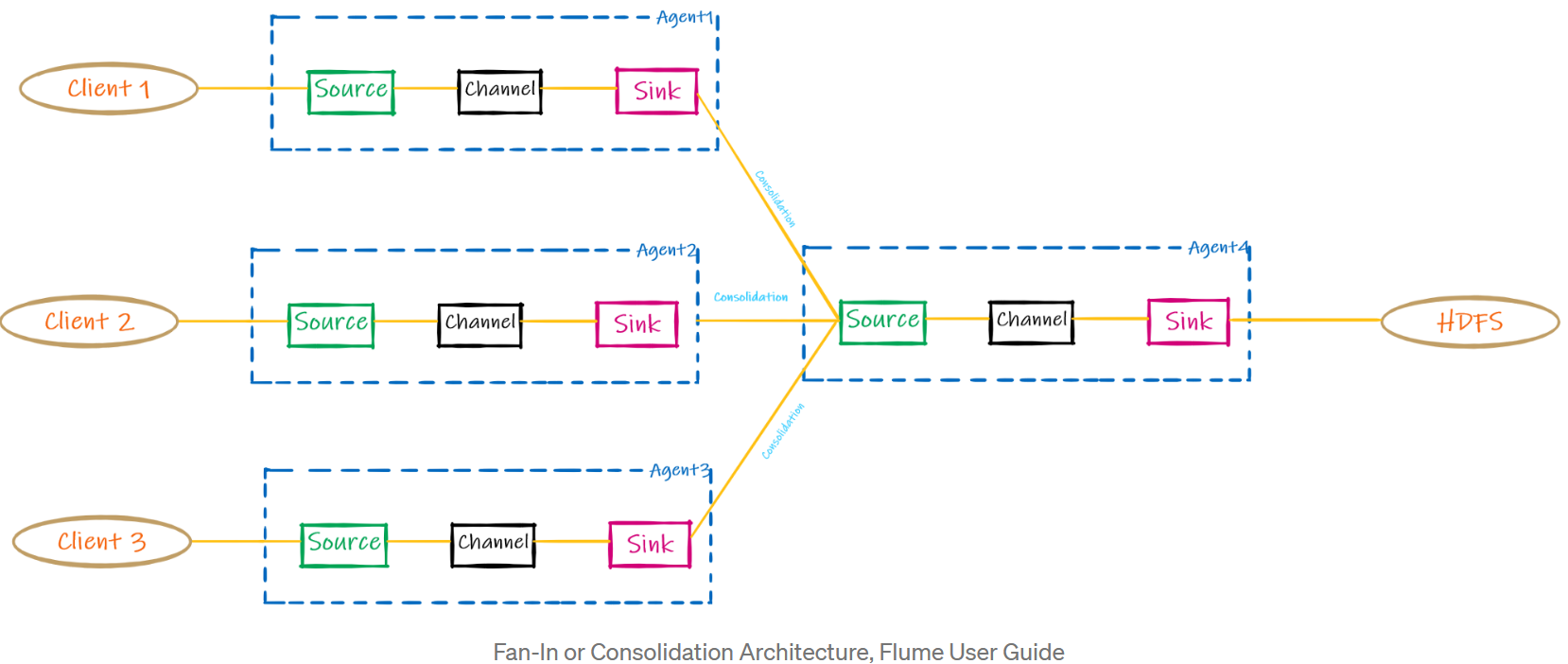
- Fan In vs Fan Out
1) Fan In
consolidate data from multiple sources on-the-fly
2) Fan Out
bifurcation of the flow. The fan-out feature hast two options, i.e. replicating and multiplexing.
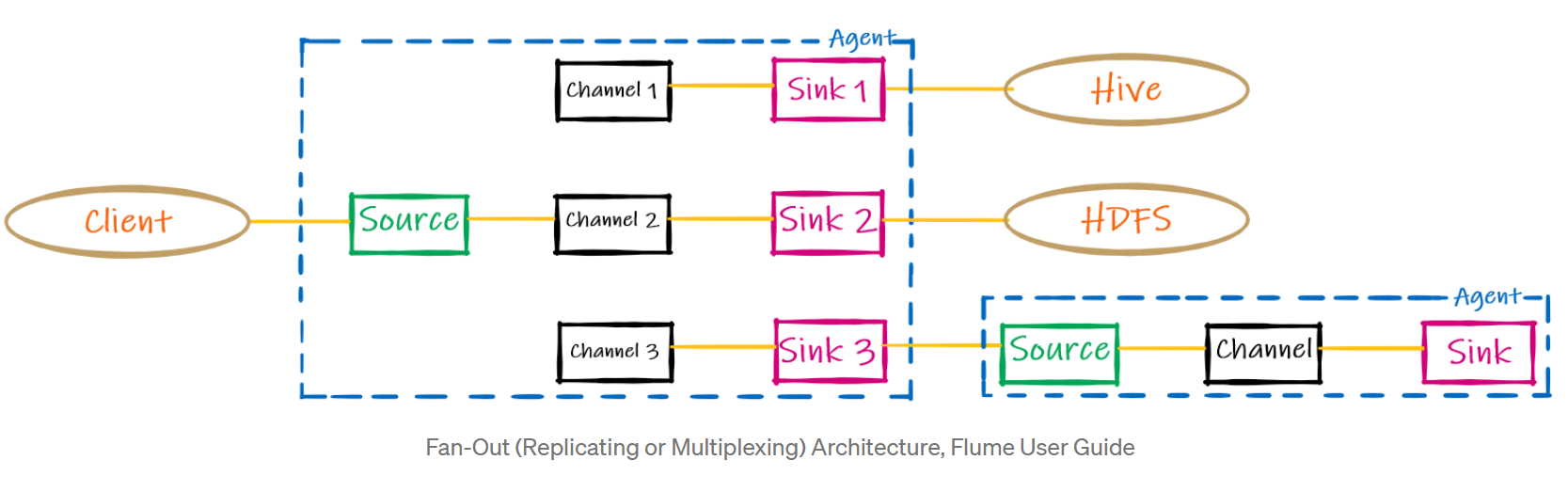
- replicating a source’s event is copied across multi channels and pushed downstream into corresponding sinks
- multiplexing multiplexing is like filtering, for example, if event is of type “Error” then push event to channel 1 and 3, else channel 2