Hive is a data repo based on Hadoop. It maps structed data file into database table and offer sql access
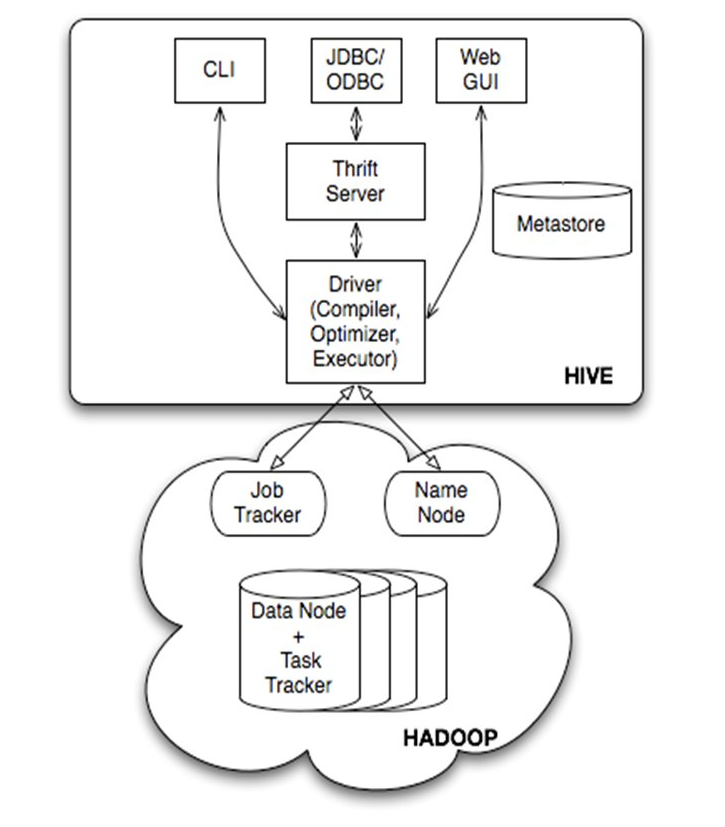
features
- feasible for static batch process
- large latency
- no add or changes on data
- query job in MapReduce form
structure
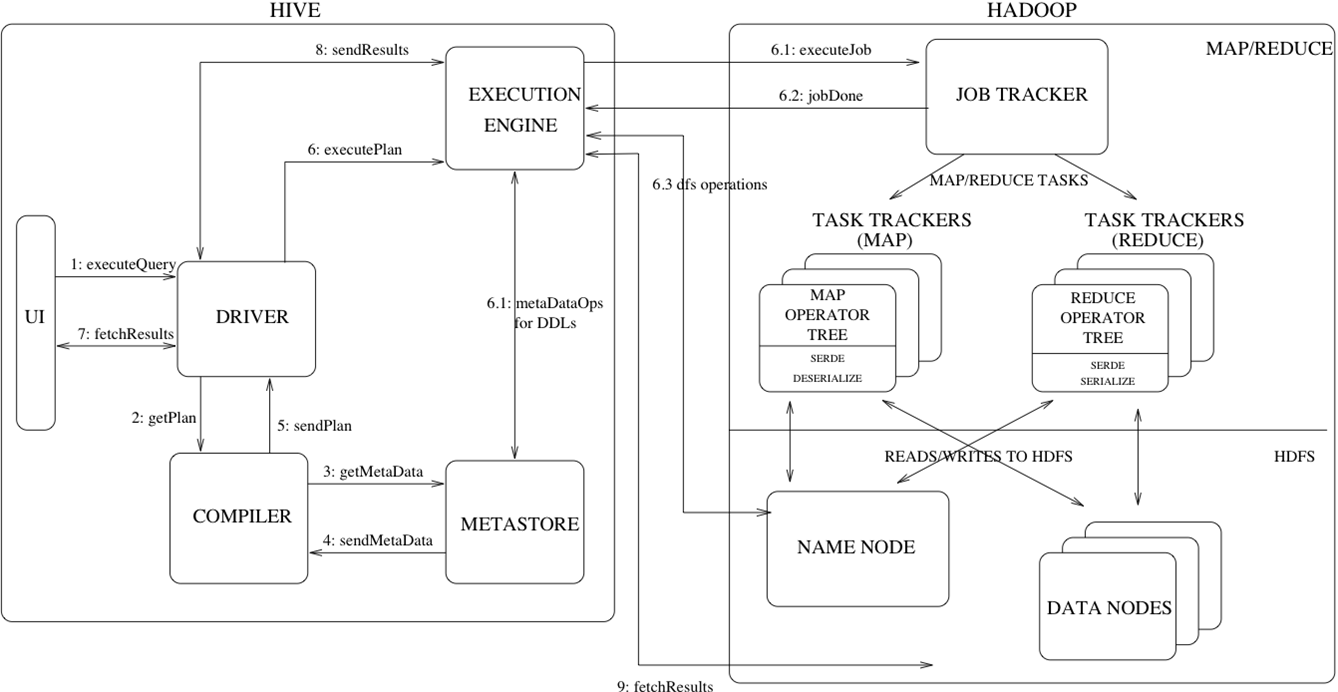
- driver: analyse hql language and interact with MapReduce framework
- metastore:metastore service and data storage(relational database).metastore service is seperated with hive service
- thrift: scalable and cross-language service development
difference with relational database
- relational database use Write-time mode to check data, hive uses read-time-mode
- relational database support update/delete on one or more rows, but hive not
- hive combined with hbase can offer real-time query
implementation
shell
hive –e create table test (value string) Load data local inpath ‘home/hadoop/test.txt’ overwrite into table test hive –e ‘select * from test’