automate machine learning project with docker, makefile and Devops tools
docker
development
Debuggable Docker Containers for Development
# dev.Dockerfile
FROM python:3.8.1-buster AS builder
RUN apt-get update && apt-get install -y --no-install-recommends --yes python3-venv gcc libpython3-dev && \
python3 -m venv /venv && \
/venv/bin/pip install --upgrade pip
FROM builder AS builder-venv
COPY requirements.txt /requirements.txt
RUN /venv/bin/pip install -r /requirements.txt
FROM builder-venv AS tester
COPY . /app
WORKDIR /app
RUN /venv/bin/pytest
FROM martinheinz/python-3.8.1-buster-tools:latest AS runner
COPY --from=tester /venv /venv
COPY --from=tester /app /app
WORKDIR /app
ENTRYPOINT ["/venv/bin/python3", "-m", "blueprint"]
USER 1001
LABEL name={NAME}
LABEL version={VERSION} ### production minimize docker image size for production
# prod.Dockerfile
# 1. Line - Change builder image
FROM debian:buster-slim AS builder
# ...
# 17. Line - Switch to Distroless image
FROM gcr.io/distroless/python3-debian10 AS runner
# ... Rest of the Dockefile
there is an debuggable version of gcr.io/distroless/python3-debian10 named gcr.io/distroless/python3-debian10:debug
# 17. Line - Switch to Distroless image:debug
FROM gcr.io/distroless/python3-debian10:debug AS runner
# ... Rest of the Dockefile
Makefile
build dev
using make build-dev to run following target
# The binary to build (just the basename).
MODULE := blueprint
# Where to push the docker image.
REGISTRY ?= docker.pkg.github.com/martinheinz/python-project-blueprint
IMAGE := $(REGISTRY)/$(MODULE)
# This version-strategy uses git tags to set the version string
TAG := $(shell git describe --tags --always --dirty)
build-dev:
@echo "\n${BLUE}Building Development image with labels:\n"
@echo "name: $(MODULE)"
@echo "version: $(TAG)${NC}\n"
@sed \
-e 's|{NAME}|$(MODULE)|g' \
-e 's|{VERSION}|$(TAG)|g' \
dev.Dockerfile | docker build -t $(IMAGE):$(TAG) -f- .
build prod
using make build-prod VERSION=1.0.0
build-prod:
@echo "\n${BLUE}Building Production image with labels:\n"
@echo "name: $(MODULE)"
@echo "version: $(VERSION)${NC}\n"
@sed \
-e 's|{NAME}|$(MODULE)|g' \
-e 's|{VERSION}|$(VERSION)|g' \
prod.Dockerfile | docker build -t $(IMAGE):$(VERSION) -f- .
build containerized env
entrypoint gets overridden by bash and container command gets overridden by argument. This way we can either just enter the container and poke around or run one off command
# Example: make shell CMD="-c 'date > datefile'"
shell: build-dev
@echo "\n${BLUE}Launching a shell in the containerized build environment...${NC}\n"
@docker run \
-ti \
--rm \
--entrypoint /bin/bash \
-u $$(id -u):$$(id -g) \
$(IMAGE):$(TAG) \
$(CMD)
build push
using make push VERSION=0.0.2 to push docker image to registry
REGISTRY ?= docker.pkg.github.com/martinheinz/python-project-blueprint
push: build-prod
@echo "\n${BLUE}Pushing image to GitHub Docker Registry...${NC}\n"
@docker push $(IMAGE):$(VERSION)
build clean
clean up docker artifacts
docker-clean:
@docker system prune -f --filter "label=name=$(MODULE)"
MLRun
works together with tools like Nuclio (serverless engine) and Kubeflow pipelines to automate the MLOps process and bring CI/CD + Git practices to data science. It provides an SDK and a Kubernetes service.
single function
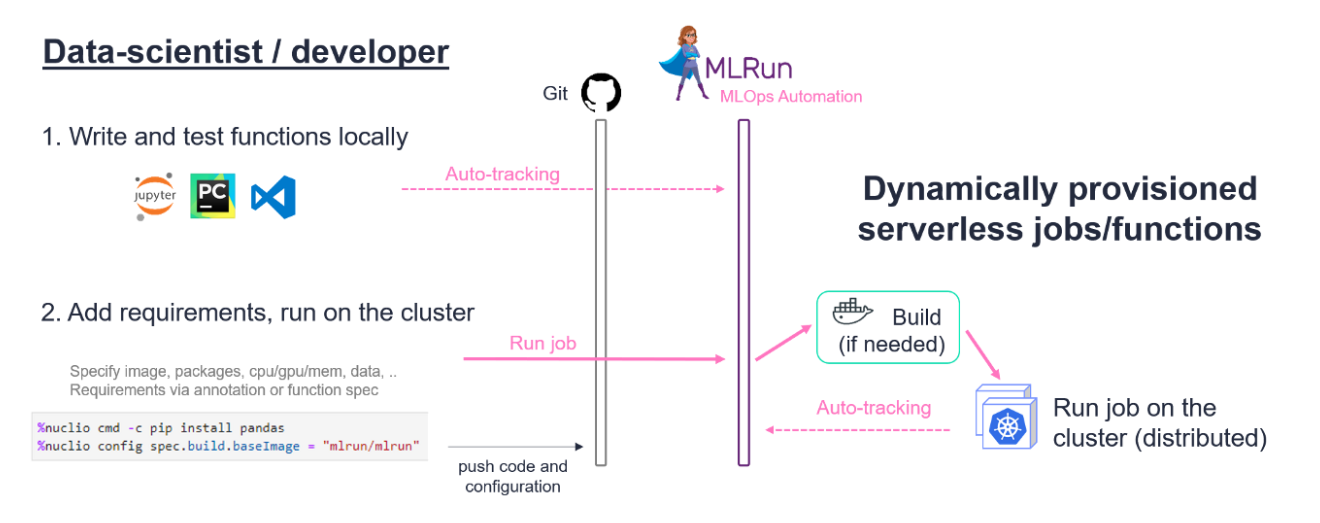 an example to mlrun function is here: https://github.com/mlrun/mlrun/blob/development/examples/mlrun_export_import.ipynb. the functions can be run in following mode:
1) As a local executable
2) As an auto-scaling containerized micro-service
3) As an in-memory module
an example to mlrun function is here: https://github.com/mlrun/mlrun/blob/development/examples/mlrun_export_import.ipynb. the functions can be run in following mode:
1) As a local executable
2) As an auto-scaling containerized micro-service
3) As an in-memory module
complex pipeline
complex pipeline can be managed by kubeflow pipeline, the kubeflow pipeline can be execuated and tracked by MLRun.
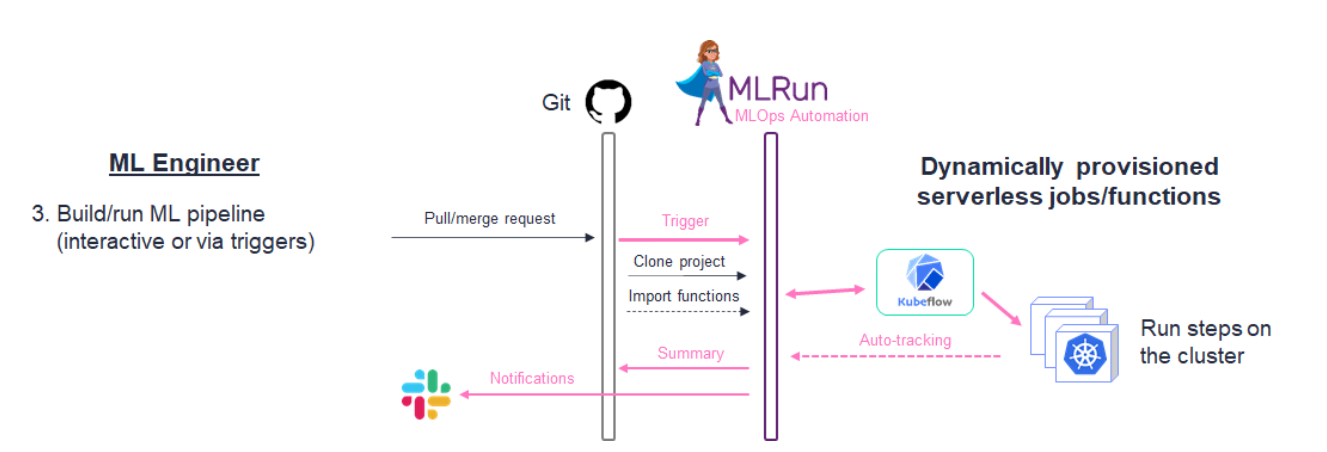 an example is here: https://github.com/mlrun/demo-github-actions
an example is here: https://github.com/mlrun/demo-github-actions