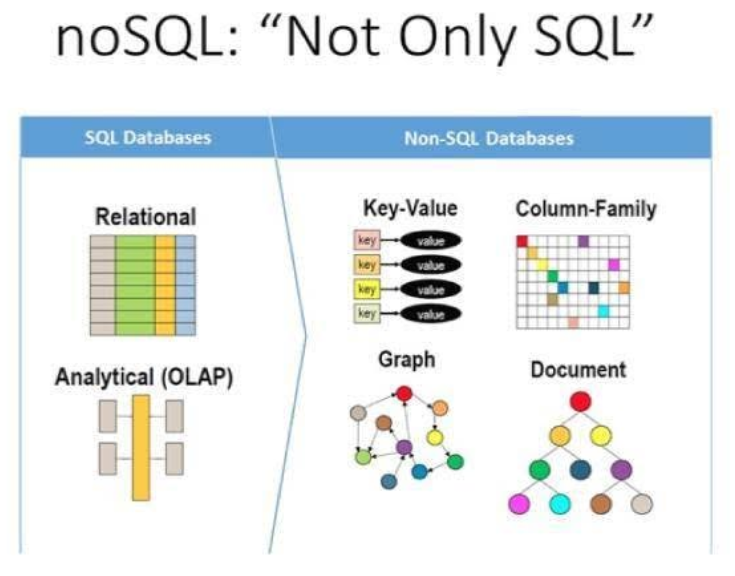
NoSQL
NoSQL database stores data in key-value pairs, wide column, graph, or document. NoSQL is more scalable than RDB, and can make full use of distributed systems to improve read and write performance and reliability. There are four types for NoSQL database:
Document-oriented.
Key-value pair.
Column-oriented.
Graph.

MongoDB
- document-oriented, use json like documents with optional schemas.
- used for simpler, more unstructured data, great for app development
redis
data from different tables are combined into a large object, and saved in the key-value format. it fits for cases that some data does not change very much, but often needs to be queried, and the query is associated with many tables. redis geo module can be used for geolocation search.
elastic search
it offer full text search
SQL
in view of programmer sql database stores data in tables with labeled rows and columns. As for how the data is stored and indexed, it is all handed over to the database. sql database has following properties:atomicity, consistency, isolation, durability.
type
Postgresql
- traditional RDBMS (relational database management system) handling more complex procedures, designs, and integrations. Mainly used for relational data, it is object-oriented in nature
- PostgreSQL scales vertically
advantages over mysql: 1) Support geographic information processing extension 2) PostgREST is able to create rest API quickly 3) Support tree structure 4) extremely powerful SQL programming skills 5) support external data sources 6) no string length limitation 7) Stronger support for indexes 8) support cluster setup 9) Transaction isolation is better 10) supports larger data volume 11) easier to add columns
MySQL
mysql advantages over postgres: 1) rollback performs better 2) more fitable for windows 3) resource usage is more efficient because of thread mode 4) More complete permissions settings 5) Storage engine plug-in mechanism 6) more fitable for simple use cases
Tips
SQLAlchemy toolkits
Column Properties
class User(Base):
__tablename__ = 'user'
id = Column(Integer, primary_key=True)
firstname = Column(String(50))
lastname = Column(String(50))
fullname = column_property(firstname + " " + lastname)
credit_card = relationship(CreditCard, backref='report')
has_credit_card = column_property(
exists().where(CreditCard.user_id == id)
)
Hybrid Properties
Hybrid properties however, produce value from Python expression on instance level and SQL expression on class level
class Order(Base):
__tablename__ = 'order'
id = Column(Integer, primary_key=True)
user_id = Column(Integer, ForeignKey('user.id'))
state = Column(String(20)) # Pending/Complete
class User(Base):
__tablename__ = 'user'
id = Column(Integer, primary_key=True)
orders = relationship("Order")
name = Column(String(50))
@hybrid_property
def has_pending_orders(self):
return any(order.state == "Pending" for order in self.orders) # -> produces value
Mixins
Defining functions as Mixins allows us to make them reusable and add them to other models without copy-pasting same code everywhere.
class MixinAsDict:
def as_dict(self):
return {c.name: getattr(self, c.name) for c in self.__table__.columns}
class MixinGetByUsername:
username = Column(String(200), unique=True, nullable=True)
@classmethod
def get_by_username(cls, username):
return session.query(cls).filter(cls.username == username).first()
class User(MixinAsDict, MixinGetByUsername, Base):
__tablename__ = 'user'
id = Column(Integer, primary_key=True)
user = User(id=1, username="John")
print(user.as_dict())
# {'username': 'John', 'id': 1}
session.add(user)
session.commit()
john = User.get_by_username("John")
print(f"User: {john.username} with ID: {john.id}")
# User: John with ID: 1
Metadata
access table column names, check constraints on the table or maybe check if columns is nullable
class Address(Base):
__tablename__ = 'address'
id = Column(Integer, primary_key=True)
user_id = Column(Integer, ForeignKey('user.id'), nullable=True)
street = Column(String(50))
class User(Base):
__tablename__ = 'user'
id = Column(Integer, primary_key=True)
firstname = Column(String(50))
lastname = Column(String(50))
address = relationship(Address, backref='report')
Base.metadata.create_all(engine)
meta = Base.metadata # Metadata()
for t in meta.sorted_tables:
print(t.name)
# user
# address
print(meta.tables["user"].c)
# ['user.id', 'user.firstname', 'user.lastname']
print(meta.tables["user"].c["lastname"].type)
# VARCHAR(50)
print(meta.tables["user"].c["lastname"].nullable)
# True
print(meta.tables["address"].foreign_keys)
# {ForeignKey('user.id')}
print(meta.tables["address"].primary_key)
# PrimaryKeyConstraint(Column('id', Integer(), table=<address>, primary_key=True, nullable=False))
Configuring Tables
class Card(Base):
__tablename__ = 'card'
__table_args__ = (
CheckConstraint("created < valid_until", name="validity_check"),
CheckConstraint("card_type ~* '^(debit|credit){1}$''", name="type_check"),
Index("index", "id"),
ForeignKeyConstraint(['id'], ['remote_table.id']),
{'extend_existing': True, "schema": "default"},
)
id = Column(Integer, primary_key=True)
created = Column(Date)
valid_until = Column(Date)
card_type = Column(String(50))
Custom Dialects
from uuid import uuid4
from sqlalchemy.dialects.postgresql import UUID, INT4RANGE, NUMRANGE, JSON
engine = create_engine('postgresql+psycopg2://postgres:postgres@localhost/testdb', echo=True)
class Example(Base):
__tablename__ = 'example'
id = Column(Integer, primary_key=True)
uuid = Column(UUID(as_uuid=True), unique=True, nullable=False, default=uuid4)
int_range = Column(INT4RANGE)
num_range = Column(NUMRANGE)
pg_json = Column(JSON)
pg_array = Column(postgresql.ARRAY(Integer), server_default='{}')
from psycopg2.extras import NumericRange
example = Example(
uuid=uuid4(),
int_range=NumericRange(1, 3),
num_range=NumericRange(1, 3),
pg_json={"key": "value"},
pg_array=[1, 5, 7, 24, 74, 8],
)
print(session.query(Example).filter(Example.pg_array.contains([5])).scalar())
# SELECT * FROM example WHERE example.pg_array @> [5]
# <__main__.Example object at 0x7f2d600a4070> # Object we previously inserted
print(session.query(Example).filter(Example.pg_json["key"].astext == "value").scalar())
Full-text Search
class MixinSearch:
@classmethod
def fulltext_search(cls, session, search_string, field):
return session.query(cls). \
filter(func.to_tsvector('english', getattr(cls, field)).match(search_string, postgresql_regconfig='english')).all()
class Book(MixinSearch, Base):
__tablename__ = 'book'
id = Column(Integer, primary_key=True)
title = Column(String(100))
body = Column(Text)
book = Book(
title="The Catcher in the Rye",
body="""First page of the book..."""
)
success = Book.fulltext_search(session, "David & Copperfield", "body")
# SELECT *
# FROM book
# WHERE to_tsvector(english, book.body) @@ to_tsquery('english','David & Copperfield')
print(success)
# [<__main__.Book object at 0x7fdac5e44520>]
fail = Book.fulltext_search(session, "cat & dog", "body")
# SELECT *
# FROM book
# WHERE to_tsvector(english, book.body) @@ to_tsquery('english', 'cat & dog')
print(fail)
# []
Tracking Last Update on Rows
class Example(Base):
__tablename__ = 'example'
id = Column(Integer, primary_key=True)
updated_at = Column(DateTime(timezone=True), server_default=func.now(), onupdate=func.now())
data = Column(String(100))
example = Example(
data="Some data..."
)
row = session.query(Example).scalar()
print(row.updated_at)
# 10:13:14.001813+00:00
time.sleep(...)
row.data = "Some new data..."
session.add(row)
session.commit()
row = session.query(Example).scalar()
print(row.updated_at)
Self-Referencing Tables
class Node(Base):
__tablename__ = 'node'
id = Column(Integer, primary_key=True)
parent_id = Column(Integer, ForeignKey('node.id'))
data = Column(String(50))
children = relationship("Node",
backref=backref('parent', remote_side=[id])
)
def __str__(self, level=0):
ret = f"{' ' * level} {repr(self.data)} \n"
for child in self.children:
ret += child.__str__(level + 1)
return ret
def __repr__(self):
return self.data
node = Node(
data="Node 1",
children=[
Node(data="Node 2"),
Node(
data="Node 3",
children=[
Node(data="Node 5")
]
),
Node(data="Node 4"),
]
)
rows = session.query(Node).all()
print(rows[0])
Binding Multiple Databases with Flask
# Config
SQLALCHEMY_DATABASE_URI = 'postgres+psycopg2://localhost/emea' # Europe, the Middle East and Africa
SQLALCHEMY_BINDS = {
'emea': 'postgres+psycopg2://localhost/emea', # Europe, the Middle East and Africa
'ap': 'mysqldb://localhost/ap', # Asia Pacific
'la': 'postgres+psycopg2://localhost/la', # Latin America
}
# Models
class User(db.Model):
__bind_key__ = 'emea' # Declare to which database the model belongs to
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(80), unique=True)
#engine
engine_emea = create_engine(...)
engine_ap = create_engine(...)
engine_la = create_engine(...)
session_emea = sessionmaker(bind=engine_emea)
session_ap = sessionmaker(bind=engine_ap)
session_la = sessionmaker(bind=engine_la)
hybrid database
HarperDB
- distributed DB with restful API and dynamic schema that support SQL and NoSQL including joins.
- HarperDB is 37 times faster than Mongo at less than half the price. HarperDB also has a native REST API, supports SQL on JSON, and can be easier to use and manage
- MongoDB and HarperDB are more distributed architectures, whereas PostgreSQL might be considered a monolithic architecture.
- HarperDB uses a simple pub-sub model; data is replicated by publishing data to different “chat rooms” which different nodes subscribe to and are able to be distributed horizontally.
- Both MongoDB and HarperDB scale horizontally
- HarperDB is not recommended when you need full-text indexing, highly structured relational data, strict consistency across systems, or for projects where developers are not trusted to constrain and maintain data
ODBC
ODBC stands for Open Database Connectivity, is a standardised application programming interface (API) for accessing databases
#an example to get data from database and send summary info per email
# imports for SQL data part
import pyodbc
from datetime import datetime, timedelta
import pandas as pd
# imports for sending email
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
import smtplib
date = datetime.today() - timedelta(days=7) # get the date 7 days ago
date = date.strftime("%Y-%m-%d") # convert to format yyyy-mm-dd
cnxn = pyodbc.connect(cnxn_str) # initialise connection (assume we have already defined cnxn_str)
# build up our query string
query = ("SELECT * FROM customers "
f"WHERE joinDate > '{date}'")
# execute the query and read to a dataframe in Python
data = pd.read_sql(query, cnxn)
del cnxn # close the connection
# make a few calculations
mean_payment = data['payment'].mean()
std_payment = data['payment'].std()
# get max payment and product details
max_vals = data[['product', 'payment']].sort_values(by=['payment'], ascending=False).iloc[0]
# write an email message
txt = (f"Customer reporting for period {date} - {datetime.today().strftime('%Y-%m-%d')}.\n\n"
f"Mean payment amounts received: {mean_payment}\n"
f"Standard deviation of payment amounts: {std_payments}\n"
f"Highest payment amount of {max_vals['payment']} "
f"received from {max_vals['product']} product.")
# we will built the message using the email library and send using smtplib
msg = MIMEMultipart()
msg['Subject'] = "Automated customer report" # set email subject
msg.attach(MIMEText(txt)) # add text contents
# we will send via outlook, first we initialise connection to mail server
smtp = smtplib.SMTP('smtp-mail.outlook.com', '587')
smtp.ehlo() # say hello to the server
smtp.starttls() # we will communicate using TLS encryption
# login to outlook server, using generic email and password
smtp.login('joebloggs@outlook.com', 'Password123')
# send email to our boss
smtp.sendmail('joebloggs@outlook.com', 'joebloggsboss@outlook.com', msg.as_string())
# finally, disconnect from the mail server
smtp.quit()
connect
cnxn_str = ("Driver={SQL Server Native Client 11.0};"
"Server=UKXXX00123,45600;"
"Database=DB01;"
"Trusted_Connection=yes;")
cnxn = pyodbc.connect(cnxn_str)
Query
cursor = cnxn.cursor()
cursor.execute("SELECT TOP(1000) * FROM customers")
Extract Data
data = pd.read_sql("SELECT TOP(1000) * FROM customers", cnxn)
update data
cursor = cnxn.cursor()
# first alter the table, adding a column
cursor.execute("ALTER TABLE customer " +
"ADD fullName VARCHAR(20)")
# now update that column to contain firstName + lastName
cursor.execute("UPDATE customer " +
"SET fullName = firstName + " " + lastName")
cnxn.commit()
Graph database
Graphs are extremely useful when dealing with complex relations, non-fixed schemas and large data sets