Dask is a parallel computing library that works by distributing larger computations and breaking it down into smaller computations through a task scheduler and task workers. it consists of three components:
- scheduler
- workers
- One or multiple clients
structure
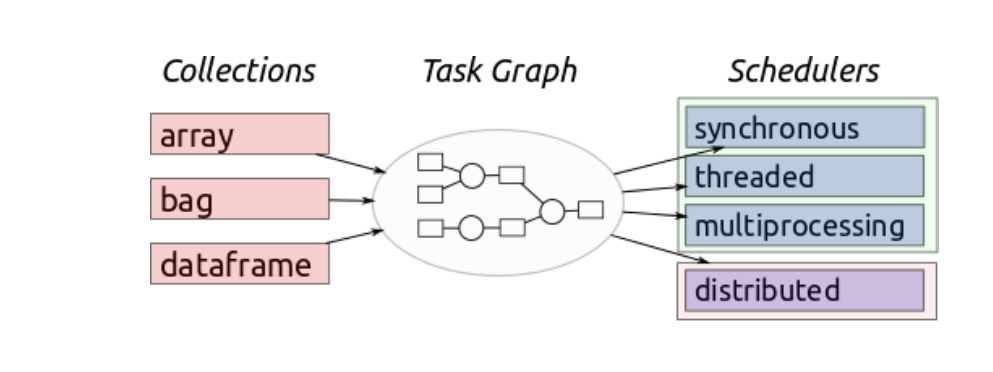
- High-level collections: Dask provides high-level Array, Bag, and DataFrame collections that mimic NumPy, lists, and Pandas but can operate in parallel on datasets that don’t fit into main memory. Dask’s high-level collections are alternatives to NumPy and Pandas for large datasets.
- Low-Level schedulers: Dask provides dynamic task schedulers that execute task graphs in parallel. Used as an alternative to direct use of threading or multiprocessing libraries in complex cases or other task scheduling systems like Luigi or IPython parallel.
Dask.array
multidimensional array composed of many small NumPy arrays

import dask.array as da
x = da.random.random((10000, 10000), chunks=(1000, 1000))
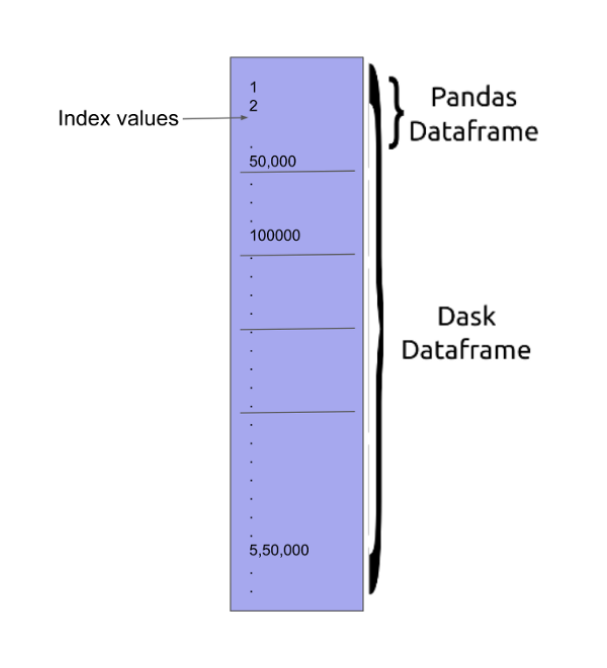
Dask.DataFrame
Dask DataFrame is a logical connection of many Pandas DataFrames
from dask import datasets
import dask.dataframe as dd
df = datasets.timeseries()
#convert pandas df to dask df
dask.dataframe.from_pandas()
#load csv to dask df
dask.dataframe.read_csv()
#load multi files into one frame
import dask.dataframe as dd
files_2019 = 's3://nyc-tlc/trip data/yellow_tripdata_2019-*.csv'
taxi = dd.read_csv(files_2019, storage_options={'anon': True}, assume_missing=True)
daskDF = taxi.persist()
_ = wait(daskDF)
Visualizing task graphs
save local image
import dask.array as da
x = da.ones((50, 50), chunks=(5, 5))
y = x + x.T
# y.compute()
y.visualize(filename='transpose.svg') #### dask dashboard
Install und usage
$ pip install dask[complete]
$ conda install dask
from dask.distributed import LocalCluster, Client
cluster = LocalCluster()
client = Client(cluster)
print(client.scheduler_info()['services'])
read csv
from dask.distributed import progress
from distributed import Client
import dask.dataframe as dd
client = Client()
dask_data=dd.read_csv('/local/home/rvshnkr/kaggle_data/NYT/train.csv')
display(dask_data.head(2))
data aggregation
def agg(variable):
agg1=dask_data.groupby([variable]).agg({'fare_amount':'mean','key':'size'}).compute().reset_index()
agg1['proportion']=100*round(agg1['key']/agg1['key'].sum(),4)
agg1['fare_amount']=round(agg1['fare_amount'],2)
display(agg1[[variable,'fare_amount','proportion']][0:8])
agg('passenger_count')
agg('year')
machine learning
columns=['passenger_count','year','fare_amount']
train_model=dask_data[columns]
train_model=train_model.sample(frac=.05, replace=False)
train_model.head()
import dask_xgboost as dxgb
params = { 'nround': 1000,
'max_depth': 16, 'eta': 0.01, 'subsample': 0.5,
'min_child_weight': 1,'scale_pos_weight':50}
labels_train, labels_test = train_model['fare_amount'].random_split([0.9, 0.1],
random_state=1234)
data_train, data_test = train_model.random_split([0.9, 0.1],
random_state=1234)
bst = dxgb.train(client, params, data_train, labels_train)
predictions = dxgb.predict(client, bst, data_test).persist()
labels=labels_test.compute()
predictions=predictions.compute()
from math import sqrt
from sklearn.metrics import mean_squared_error
Model_rmse = sqrt(mean_squared_error(labels_test, predictions))
Delayed Functions
use @dask.delayed decoration on custom functions to create delayed object
Dask-sql
SQL query engine built on top of dask, a distributed computation framework written purely in Python and playing very well with the Python ecosystem. It allows you to use normal SQL, e.g. from your favorite BI tool, and query data living in the Python space
git clone https://github.com/nils-braun/dask-sql-k8s-deployment
cd dask-sql-k8s-deployment
helm dependency update dask-sql
helm upgrade --cleanup-on-fail --install dask-sql dask-sql
kubectl port-forward svc/hue 8888:8888
#use http://localhost:8888 to access Apache Hue
machine learning in sql
connect
#connect python with dask-sql
from IPython.core.magic import register_line_cell_magic
from dask_sql import Context# Create a context to store the tables and models
c = Context()# Small helper function to make our life easier
@register_line_cell_magic
def sql(line, cell=None):
if cell is None:
cell = line
line = None
if not line:
line = {}
return c.sql(cell, return_futures=False, **line)
load data
#load data and cache it in dask-sql
CREATE OR REPLACE TABLE iris WITH (
location = 'https://datahub.io/machine-learning/iris/r/iris.csv',
persist = True
)
#check loaded data
DESCRIBE iris
#create new feature
CREATE OR REPLACE TABLE transformed_data AS (
SELECT
*,
sepallength * petallength AS new_feature
FROM iris
)
train ML model
#apply k means
CREATE OR REPLACE MODEL clustering WITH (
model_class = 'sklearn.cluster.KMeans',
wrap_predict = True,
n_clusters = 3
) AS (
SELECT sepallength, sepalwidth, petallength, petalwidth, new_feature
FROM transformed_data
)
prediction
#check performace
CREATE OR REPLACE TABLE iris_results AS (
SELECT class AS label, target AS predicted FROM PREDICT (
MODEL clustering,
SELECT * FROM transformed_data
)
)
SELECT
label, predicted, COUNT(*) AS numbers
FROM iris_results
GROUP BY label, predicted
#plot
df = c.sql("""
SELECT
label, predicted, COUNT(*) AS numbers
FROM iris_results
GROUP BY label, predicted
""", return_futures=False)df = df.set_index(["label", "predicted"])
df.numbers.unstack(0).plot.bar(ax=plt.gca())