traditional RDBMS (relational database management system). Mainly used for relational data, it is object-oriented in nature.
useful operation like in dataframe
- Specify your own custom functions
- Use recursion to create complex looping and data generation with the WITH keyword.
- Sort string columns by a substring.
- Perform complex joining between multiple tables.
- Use SQL to generate SQL (automating tasks).
- Generate forecasts using statistical models.
- Create histograms.
- Build tree structures (with leaf, branch, root nodes)
select
SELECT CustomerName || ' LIVES IN ' || Address || ', ' || City AS location
FROM Customers
WHERE Country='Mexico'
if/else
SELECT Price,
CASE WHEN Price < 12 THEN 'Cheap'
WHEN Price < 21 THEN 'Regular'
ELSE 'Expensive'
END AS Bucket
FROM Products
random select
SELECT * FROM Products ORDER BY random() LIMIT 5
index
hash index
Starting at PostgreSQL 10 these limitations were resolved, and Hash indexes are no longer discouraged. Hash index outperforms the B-Tree index with a very slight difference, but it has a much smaller index size. limitation:
- Hash index cannot be used to enforce a unique constraint
- Hash index cannot be used to create indexes on multiple columns
- Hash index cannot be used to create sorted indexes
- can’t use a Hash index to cluster a table
- Hash index cannot be used for range lookups
- A Hash index cannot be used to satisfy ORDER BY queries
Creating Hash Indexes
#an example of URL shortener service(provides a short random URL that points to a longer URL)
#table between key and full url
CREATE TABLE shorturl (
id serial primary key,
key text not null,
url text not null
);
#create a B-Tree and a Hash index on both fields (key and full url)
CREATE INDEX shorturl_key_hash_index ON shorturl USING hash(key);
CREATE UNIQUE INDEX shorturl_key_btree_index ON shorturl USING btree(key);
CREATE INDEX shorturl_url_hash_index ON shorturl USING hash(url);
CREATE INDEX shorturl_url_btree_index ON shorturl USING btree(url);
Hash Index Size
The Hash index is smaller than the B-Tree index.
CREATE EXTENSION "uuid-ossp";
DO $$
BEGIN
FOR i IN 0..1000000 loop
INSERT INTO shorturl (key, url) VALUES (
uuid_generate_v4(),
'https://www.supercool-url.com/' || round(random() * 10 ^ 6)::text
);
if mod(i, 10000) = 0 THEN
RAISE NOTICE 'rows:% Hash key% B-Tree key:% Hash url:% B-Tree url:%',
to_char(i, '9999999999'),
to_char(pg_relation_size('shorturl_key_hash_index'), '99999999999'),
to_char(pg_relation_size('shorturl_key_btree_index'), '99999999999'),
to_char(pg_relation_size('shorturl_url_hash_index'), '99999999999'),
to_char(pg_relation_size('shorturl_url_btree_index'), '99999999999');
END IF;
END LOOP;
END;
$$;
dynamic hash table
the structure of a hash table is as follows:
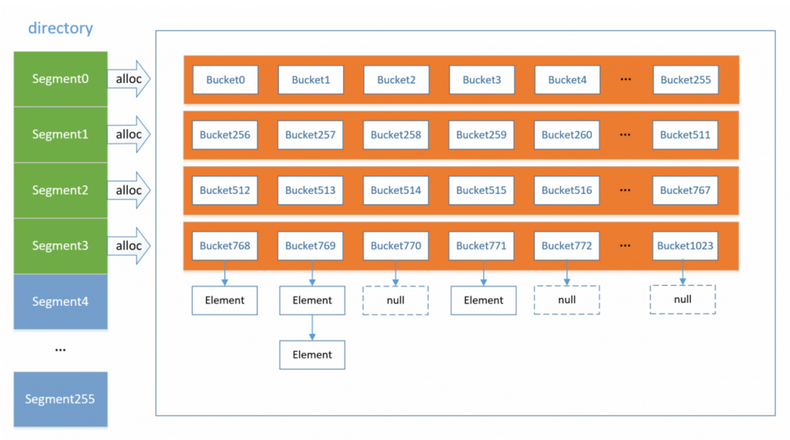 When the hash table needs to be expanded, it is added one bucket at a time, but the memory space is applied with many buckets as a segment at one time. This avoids the performance degradation caused by frequent application space. After extending a bucket, we only need to traverse the elements in the corresponding one old bucket, and then move the elements to be moved to the new bucket.
When the hash table needs to be expanded, it is added one bucket at a time, but the memory space is applied with many buckets as a segment at one time. This avoids the performance degradation caused by frequent application space. After extending a bucket, we only need to traverse the elements in the corresponding one old bucket, and then move the elements to be moved to the new bucket.
usage tips
postgresql cluster
Create a unified management, flexible cloud-native production deployment to deploy a personalized database as a service (DBaaS) on k8s. (https://github.com/CrunchyData/postgres-operator)
#config postgresql operator
wget <https://raw.githubusercontent.com/CrunchyData/postgres-operator/master/examples/quickstart.sh>
chmod +x ./quickstart.sh
./examples/quickstart.sh
#create postgresql cluster
pgo create cluster mynewcluster
pgo test mynewcluster
Postgresql operator
introduction and usage of the postgresql operator is here: https://operatorhub.io/operator/postgres-operator. a graphical user interface called postgres-operator-ui is available. different PostgreSQL roles can be defined wtih Teams API. some customized postgresql operator is also available, such as Stolon, Crunchy Data, Zalando, KubeDB, StackGres and https://github.com/flant/postgres-operator (comparision: https://blog.flant.com/comparing-kubernetes-operators-for-postgresql/) to deploy the postgresql operator following deployment manifest can be used:
apiVersion: acid.zalan.do/v1
kind: postgresql
metadata:
name: staging-db
spec:
numberOfInstances: 3
patroni:
synchronous_mode: true
postgresql:
version: "12"
resources:
limits:
cpu: 100m
memory: 1Gi
requests:
cpu: 100m
memory: 1Gi
sidecars:
- env:
- name: DATA_SOURCE_URI
value: 127.0.0.1:5432
- name: DATA_SOURCE_PASS
valueFrom:
secretKeyRef:
key: password
name: postgres.staging-db.credentials
- name: DATA_SOURCE_USER
value: postgres
image: wrouesnel/postgres_exporter
name: prometheus-exporter
resources:
limits:
cpu: 500m
memory: 100Mi
requests:
cpu: 100m
memory: 100Mi
teamId: staging
volume:
size: 2Gi
monitoring postgres on kubernetes
#deploy monitoring pod
kubectl apply -f https://raw.githubusercontent.com/CrunchyData/postgres-operator/v4.5.0/installers/metrics/kubectl/postgres-operator-metrics.yml
#collect data
pgo create cluster hippo --metrics --replica-count=1
pgo create cluster rhino --metrics --replica-count=1
pgo create cluster zebra --metrics
Postgres Notify for Real Time Dashboards
with the NOTIFY and LISTEN commands we can implement something akin to the Observer pattern in SQL engine. The Observer pattern allows one class of object to “listen” for incoming events and another class to send events to those listeners.
Oberver pattern
observers can be created to watch for changes and immediately update the state and UI of an app.
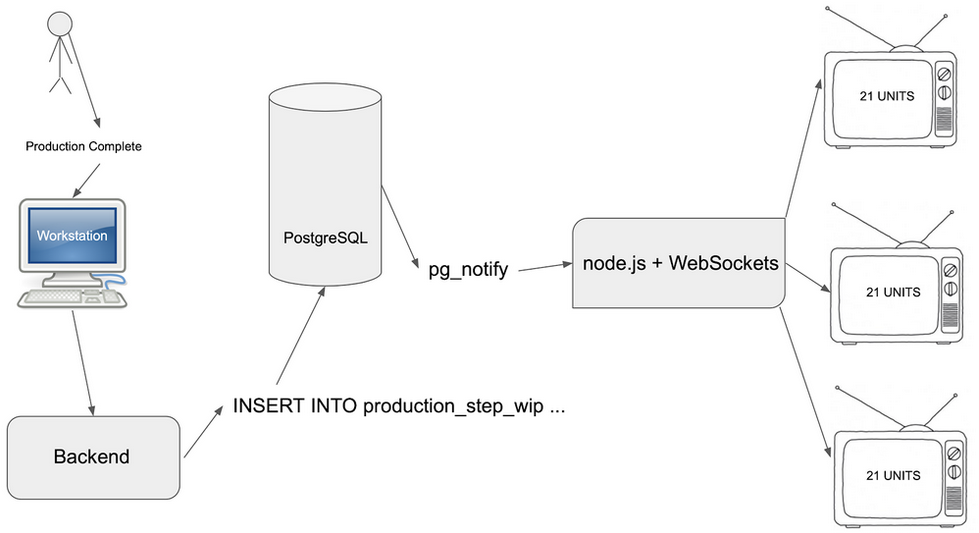
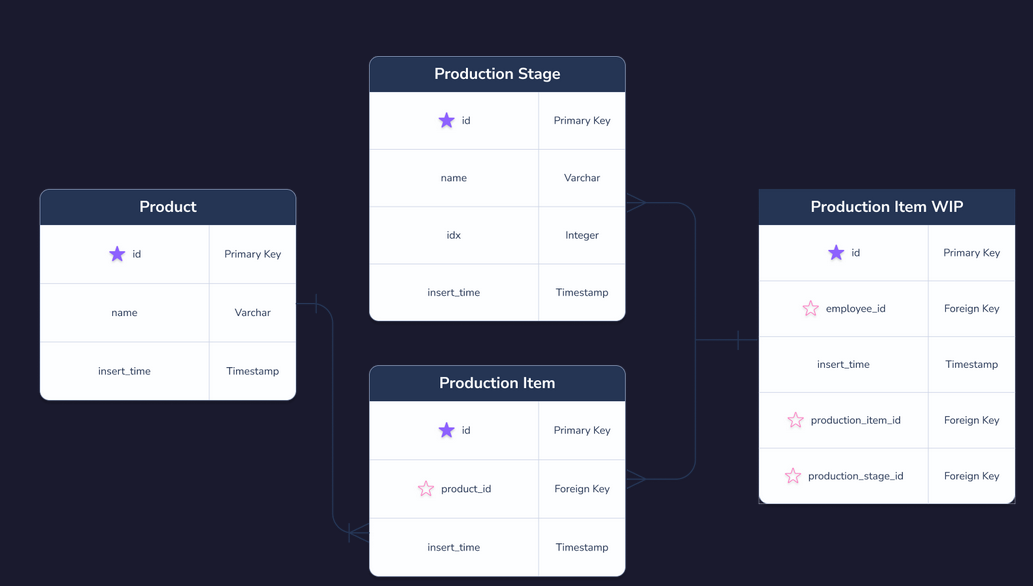
#create production item work in progress
create table production_item_wip (
id serial primary key,
insert_time timestamp default NOW(),
production_item_id int references production_item(id),
production_stage_id int references production_stage(id),
employee_id int references employee(id)
);
#create NOTIFY syntax
create
or replace function fn_production_stage_modified() returns trigger as $psql$
begin
perform pg_notify(
'order_progress_event',
'Time to refresh those screens!'
);return new;
end;$psql$ language plpgsql;
#create trigger
create trigger production_stage before
insert
on production_item_wip for each row execute procedure fn_production_stage_modified();
LISTEN pattern
Listening pattern is like this: LISTEN order_progress_event;
#create view showing how many products have progressed through each production stage today
create view view_daily_production_stats as
select
count(1) as stage_count,
ps.name as stage_namefrom production_item_wip piw
join production_stage ps on ps.id = piw.production_stage_idwhere date(piw.insert_time) = date(now())
group by
ps.id
#callback function
var clients = [];
function eventCallback(event) {
query('select * from view_daily_production_stats', (data) => {
clients.map(c => {
c.send(data);
});
});
}
client.connect(function(err, client) {
var query = client.query("LISTEN order_progress_event");
client.on("notification", eventCallback);
});
;