Methods
LDA
# initisalise LDA Model
lda_model = LatentDirichletAllocation(n_components = 10, # number of topics
random_state = 10, # random state
evaluate_every = -1, # compute perplexity every n iters, default: Don't
n_jobs = -1, # Use all available CPUs
)
lda_output = lda_model.fit_transform(vectorised)
# column names
topic_names = ["Topic" + str(i) for i in range(1, lda_model.n_components + 1)]
# make the pandas dataframe
df_document_topic = pd.DataFrame(np.round(lda_output, 2), columns = topic_names)
# get dominant topic for each document
dominant_topic = (np.argmax(df_document_topic.values, axis=1)+1)
df_document_topic['Dominant_topic'] = dominant_topic
# join to original dataframes
df = pd.merge(df, df_document_topic, left_index = True, right_index = True, how = 'outer')
display(df.head(10))
#to see the keywords in topic lists
keywords = np.array(vectorizer.get_feature_names())
topic_keywords = []
for topic_weights in lda_model.components_:
top_keyword_locs = (-topic_weights).argsort()[:20]
topic_keywords.append(keywords.take(top_keyword_locs))
for i in topic_keywords:
print(i)
Rapid Automatic Keyword Extraction (RAKE)
a well-known keyword extraction tool which uses a list of stop words and phrase delimiters to detect the most relevant words or phrases in a piece of text
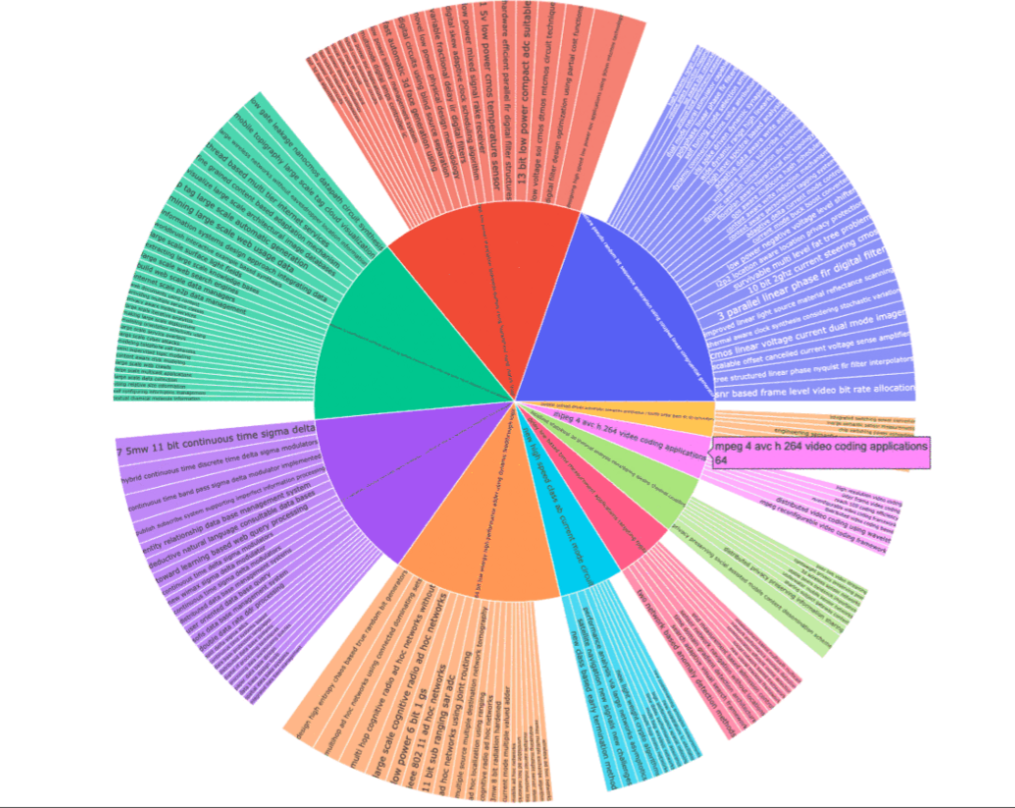
all_results = []
for i in df['Dominant_topic'].unique():
topic = df[df['Dominant_topic'] == i]
topic = topic.copy()
# remove punctuation
topic[0] = topic[0].str.lower().str.replace('[^\w\s]', ' ').str.replace(' +', ' ').str.strip()
key_words = []
# run keyword extraction
for j in topic[0].values.tolist():
r = Rake()
a = r.extract_keywords_from_text(j)
c = r.get_ranked_phrases_with_scores()
for k in c:
if k not in key_words:
key_words.append(k)
key_words = pd.DataFrame(key_words, columns =['score', 'term'])
key_words = key_words.sort_values('score', ascending=False)
key_words = key_words.drop_duplicates(subset=['term'])
key_words['topic_number'] = i
key_words['term_list'] = key_words.term.apply(lambda x: x.split())
# find bigrams from key words to match against topic modelling output
tmp_keywords = []
for j in key_words.values.tolist():
tmp = []
bi_grams = ngrams(j[3], 2)
for g in bi_grams:
tmp.append(' '.join(g))
for k in j[3]:
tmp.append(k)
# lemmatise words to match the lemmatised output of the topic modelling word extraction
tmp.append(wordnet_lemmatizer.lemmatize(k))
j.remove(j[3])
j.append(list(set(tmp)))
tmp_keywords.append(j)
# mask key words against topic modelling output
key_words = pd.DataFrame(tmp_keywords, columns =['score', 'term', 'topic_number', 'term_list'])
topic_keywords = topic['Topic_keywords'].values.tolist()
topic_keywords = [item for sublist in topic_keywords for item in sublist]
topic_keywords = list(set(topic_keywords))
tmp = []
for t in topic_keywords:
mask = key_words.term_list.apply(lambda x: t in x)
key_words_processed = key_words[mask]
if key_words_processed.empty:
pass
else:
for j in key_words_processed[['score', 'term', 'topic_number']].values.tolist():
if j not in tmp:
tmp.append(j)
key_words = pd.DataFrame(tmp, columns =['score', 'term', 'topic_number'])
# select the max score as the topic title
top_key_words = key_words[key_words.score == key_words['score'].max()]
# select the remaining keywords as child terms
remaining_keywords = key_words[key_words.score != key_words['score'].max()]
# if there are more than 1 keyword in the topic title, aggregate them with a / as a separatore
top_key_words = top_key_words.copy()
top_key_words = top_key_words.groupby(['score', 'topic_number']).agg({'term' : lambda x: ' / '.join(map(str, x))})
top_key_words = top_key_words.reset_index()
# add 0.1 to the child keywords to identify then in the merged dataframe
remaining_keywords = remaining_keywords.copy()
remaining_keywords['topic_number'] = remaining_keywords['topic_number'] + 0.1
all_topics = pd.concat([top_key_words, remaining_keywords], sort=False)
for t in all_topics.to_dict(orient='records'):
all_results.append(t)
all_topics_df = pd.DataFrame(all_results)
all_topics_df = all_topics_df.sort_values('topic_number', ascending=True)
NMF
BERT
example
get data
if needed the data can be splitted in paragraph, so that topic modeling is done on paragraph level
from sklearn.datasets import fetch_20newsgroups
data = fetch_20newsgroups(subset='all')['data']
create embedding
converting the documents to numerical data
#pip install sentence-transformers
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('distilbert-base-nli-mean-tokens')
embeddings = model.encode(data, show_progress_bar=True)
clustering
cluster documents with similar topics together
dimension reduction with UMAP
best performance in keeping a significant portion of the high-dimensional local structure in lower dimensionality, this step is optional
#pip install umap-learn
import umap
umap_embeddings = umap.UMAP(n_neighbors=15, n_components=5, metric='cosine').fit_transform(embeddings)
clusting with HDBSAN
#pip install hdbscan
import hdbscan
cluster = hdbscan.HDBSCAN(min_cluster_size=15, metric='euclidean', cluster_selection_method='eom').fit(umap_embeddings)
visualize with plt
import matplotlib.pyplot as plt
# Prepare data
umap_data = umap.UMAP(n_neighbors=15, n_components=2, min_dist=0.0, metric='cosine').fit_transform(embeddings)
result = pd.DataFrame(umap_data, columns=['x', 'y'])
result['labels'] = cluster.labels_
# Visualize clusters
fig, ax = plt.subplots(figsize=(20, 10))
outliers = result.loc[result.labels == -1, :]
clustered = result.loc[result.labels != -1, :]
plt.scatter(outliers.x, outliers.y, color='#BDBDBD', s=0.05)
plt.scatter(clustered.x, clustered.y, c=clustered.labels, s=0.05, cmap='hsv_r')
plt.colorbar()
Topic Creation
derive topics from clustered documents
c-TF-IDF
class-based variant of TF-IDF that allow to extract what makes each set of documents unique compared to the other. It generates importance value for each word in a cluster which can be used to create the topic
docs_df = pd.DataFrame(data, columns=["Doc"])
docs_df['Topic'] = cluster.labels_
docs_df['Doc_ID'] = range(len(docs_df))
docs_per_topic = docs_df.groupby(['Topic'], as_index = False).agg({'Doc': ' '.join})
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
def c_tf_idf(documents, m, ngram_range=(1, 1)):
count = CountVectorizer(ngram_range=ngram_range, stop_words="english").fit(documents)
t = count.transform(documents).toarray()
w = t.sum(axis=1)
tf = np.divide(t.T, w)
sum_t = t.sum(axis=0)
idf = np.log(np.divide(m, sum_t)).reshape(-1, 1)
tf_idf = np.multiply(tf, idf)
return tf_idf, count
tf_idf, count = c_tf_idf(docs_per_topic.Doc.values, m=len(data))
Topic Representation
def extract_top_n_words_per_topic(tf_idf, count, docs_per_topic, n=20):
words = count.get_feature_names()
labels = list(docs_per_topic.Topic)
tf_idf_transposed = tf_idf.T
indices = tf_idf_transposed.argsort()[:, -n:]
top_n_words = {label: [(words[j], tf_idf_transposed[i][j]) for j in indices[i]][::-1] for i, label in enumerate(labels)}
return top_n_words
def extract_topic_sizes(df):
topic_sizes = (df.groupby(['Topic'])
.Doc
.count()
.reset_index()
.rename({"Topic": "Topic", "Doc": "Size"}, axis='columns')
.sort_values("Size", ascending=False))
return topic_sizes
top_n_words = extract_top_n_words_per_topic(tf_idf, count, docs_per_topic, n=20)
topic_sizes = extract_topic_sizes(docs_df); topic_sizes.head(10)
Topic Reduction
for i in range(20):
# Calculate cosine similarity
similarities = cosine_similarity(tf_idf.T)
np.fill_diagonal(similarities, 0)
# Extract label to merge into and from where
topic_sizes = docs_df.groupby(['Topic']).count().sort_values("Doc", ascending=False).reset_index()
topic_to_merge = topic_sizes.iloc[-1].Topic
topic_to_merge_into = np.argmax(similarities[topic_to_merge + 1]) - 1
# Adjust topics
docs_df.loc[docs_df.Topic == topic_to_merge, "Topic"] = topic_to_merge_into
old_topics = docs_df.sort_values("Topic").Topic.unique()
map_topics = {old_topic: index - 1 for index, old_topic in enumerate(old_topics)}
docs_df.Topic = docs_df.Topic.map(map_topics)
docs_per_topic = docs_df.groupby(['Topic'], as_index = False).agg({'Doc': ' '.join})
# Calculate new topic words
m = len(data)
tf_idf, count = c_tf_idf(docs_per_topic.Doc.values, m)
top_n_words = extract_top_n_words_per_topic(tf_idf, count, docs_per_topic, n=20)
topic_sizes = extract_topic_sizes(docs_df); topic_sizes.head(10)