data transformation
数据转换成图像
元数据泄露
当处理过的特征在没有应用任何机器学习的情况下,可以非常完美地解释目标时,这可能发生了数据泄露
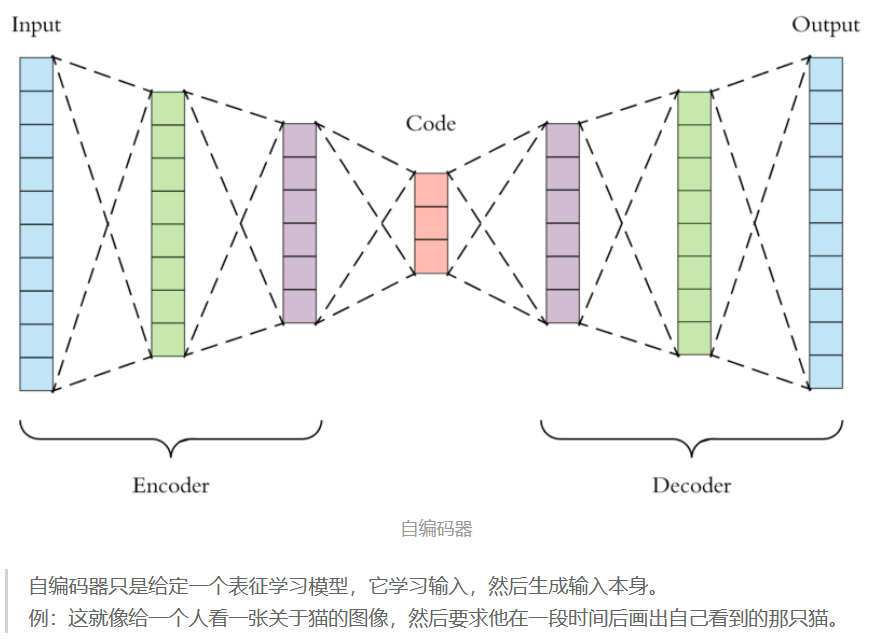
表征学习特征
法直接从训练数据中捕捉最显著的特征,无需其他特征工程。
均值编码
数据分析中经常会遇到类别属性,比如日期、性别、街区编号、IP地址等。绝大部分数据分析算法是无法直接处理这类变量的,需要先把它们先处理成数值型量。如果这些变量的可能值很少,我们可以用常规的one-hot编码和label encoding。但是,如果这些变量的可能值很多, 均值编码是最好的选择之一。但它也有缺点,就是容易过拟合(因为提供了大量数据),所以使用时要配合适当的正则化技术。
转换目标变量
对高度偏斜的数据,如果我们把目标变量转成log(1+目标)格式,那么它的分布就接近高斯分布了
feature engine
Feature-engine is one feature enginerring package in python3
Installation
pip install feature-engine
data cleaning
1) filling missing data
edian_imputer = MeanMedianImputer(
imputation_method='median',
variables=[‘A2’, ‘A3’, ‘A8’, ‘A11’, ‘A15’]
)
median_imputer.fit(X_train)
X_train = median_imputer.transform(X_train)
X_test = median_imputer.transform(X_test)
2) convert categorical to numerical
encoder = ce.CountFrequencyEncoder(
encoding_method='frequency',
variables=['cabin', 'pclass', 'embarked']
)
encoder.fit(X_train)
train_t = encoder.transform(X_train)
test_t = encoder.transform(X_test)
print(encoder.encoder_dict_)
3) Discretization
disc = dsc.DecisionTreeDiscretiser(
cv=3,
scoring='neg_mean_squared_error',
variables=['LotArea', 'GrLivArea'],
regression=True
)
disc.fit(X_train, y_train)
train_t = disc.transform(X_train)
test_t = disc.transform(X_test)
4) transformation
tf = vt.BoxCoxTransformer(
variables = ['LotArea', 'GrLivArea']
)
tf.fit(X_train)
train_t = tf.transform(X_train)
test_t = tf.transform(X_test)
5) Outlier handling
capper = outr.Winsorizer(
distribution='gaussian',
tail='right',
fold=3,
variables=['age', 'fare']
)
capper.fit(X_train)
train_t = capper.transform(X_train)
test_t = capper.transform(X_test)